In my first post about Node.js I want to teach you how to get content from websites that don't provide an API.
What?
At my company right before lunch there appears always the same question: "What do we eat for lunch today? Are there and special offers today?". We have a lot of restaurants around and quite a lot of them have daily offers. Some of them are providing the information on their website. This is good! We are handling our communication at work through Slack. So I'd like to have this daily offers posted to one of our channels (we have an special "lunch" channel for this). Because there is nothing that can offer this feature, I was coming up with my own solution. This post will cover the first part of scraping the daily offer of a website and have it available for further usage.
Prerequisites
You need to have Node 8+ installed on your system and access to your favorite terminal application, to verify this execute:
node -v # should return something like v8.9.0
Groundwork
First you have to create a folder for the project (you can do this in your preffered way or by following command)
mkdir lunch-menu-scraper
Then switch to the new created directory and add a file 'index.js' by running:
cd lunch-menu-scraper
touch index.js

The next step is to add a library called ScrapeIt through npm, you can either use npm or yarn for doing this.
# Using npm
npm install --save scrape-it
# Using yarn
yarn add scrape-it
Study page structure
The page we are going to scrape is: Schroedingers (sadly only available in german, but you can easily adapt the process to other sites aswell). From monday to friday they have one or two daily offers; this is the information that we want to get.
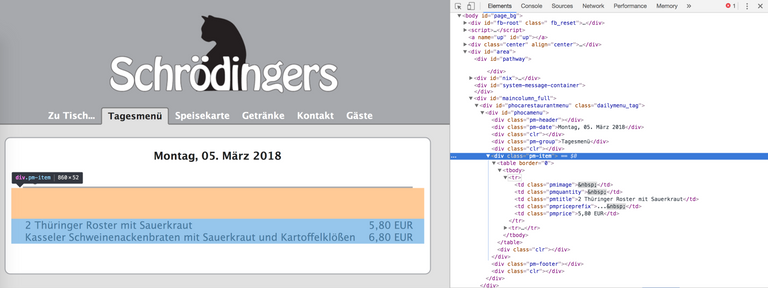
Implement the logic
The library scrape-it uses css-selectors to scrape websites, so we need to scan the html structure of the page where to find our information. We can see in the picture above that the dishes are surrounded by a div.pm-item. Each dish has it's own tr and we can get the name of the dish by .pmtitle and the price by .pmprice.
const scrapeIt = require("scrape-it");
async function run() {
const response = await scrapeIt("http://www.schroedingers.de/tagesmenue", {
dishes: {
listItem: '.pm-item tr',
data: {
name: '.pmtitle',
price: '.pmprice'
}
}
});
console.log(response.dishes);
}
run();
Short explanation to the code itself:
First we import the scrape-it library, then we define an async function so we can make usage of await. Then we call the scrapeIt function, as the first parameter we put the url of the website, the second parameter is an options object describing how the output should look like. dishes is going to be an array of objects containing name and price.
When you execute the code above by:
node index.js
we get the output:
[
{
name: '2 Thüringer Roster mit Sauerkraut',
price: '5,80 EUR'
},
{
name: 'Kasseler Schweinenackenbraten mit Sauerkraut und Kartoffelklößen',
price: '6,80 EUR'
}
]
We can use this array for further operations like posting a notification with this content to a specific slack channel, so other people also know what is available for offer today. I will cover this case in an upcoming post.
Thanks for reading
If you enjoyed this post about how to scrape a website with Node.js then consider giving me an upvote or follow me to always see my latest development posts.
Also if you have any questions or tips how to improve my posts, feel free to leave a comment. I'm very eager to learn. :)
Thank you for this simple tutorial. You have earned my upvote :)
Super das es dir gefällt! Ich werde versuchen dieses Wochenende etwas neues zu veröffentlichen! Hast du ansonsten Themen für die Zukunft über die ich schreiben könnte? Würde dich ein Beitrag über einen crypto slack bot interessieren?