운영체제
linux, MacOS, windows, ios, etc.
"왜 탄생하였나?"
공통으로 사용하는 하드웨어와 소프트웨어를 운영하는 프로그램이 필요하게 되었다.
커널 - 뼈대
운영체제
<li><strong>시스템 하드웨어 관리</strong></li>
사용자 프로그램의 오류나 잘못된 자원 사용을 감시
입출력 장치 등의 자원에 대한 연산과 제어를 관리
<li><strong>가상시스템 서비스 제공</strong></li>
사용자에게 컴퓨터의 프로그램을 쉽고 효율적어로 실행할 수 있는 환경 제공
<li><strong>자원관리</strong></li>
컴퓨터 시스템 하드웨어 및 소프트웨어 자원을 여러 사용자 간에 효율적 할당, 관리, 보호
프로세스관리
프로세스마다 얼만큼의 자원을 사용할 것인가 결정하는 것
비선점 스케줄링 (Non-Preemptive)
할당된 cpu를 다른 프로세스가 강제로 뺏어 사용할 수 없는 기법
한번 cpu를 할당받으면 작업이 완료될 때까지 cpu를 사용
문제점: 짧은(중요한)작업이 긴 작업을 기다리는 경우 발생
종류:
FCFSM SJF, HRN, Deadline(기한부)
FCFS(First Come First Served)
FIFO
<li><strong>SJF(Shortest Job First)</strong></li>
짧은거 먼저 프로세싱
평균대기시간 가장 적은 알고리즘
정확한 처리시간을 알 수 가 없고, 처리측정하는 비용도 발생
일정시간동안 프로세스 완료하는 기법
제한시간 완료안될 경우 제거되거나 처음부터 다시 실행
스케줄링이 복잡해지며, 프로세스 실행시 집중적으로 요구되는 자원관리에 요구되는 자원관리에 오버해드가 발생
프로세스마다 우선순위 부여
우선순위가 동일한 경우 FCFS기법으로 할당
가장 낮은 순위를 부여받은 프로세스의 무한연기 발생가능
Preemptive(선점 스케줄링)
우선순위가 높은 프로세스가 강제로 cpu를 빼앗아 사용할 수 있는 기법
대화식 시분할 시스템(Time Sharing System)
단점-많은 오버헤드, 인터럽트용 타이머클럭 필요
종류:
RR(Round Robin), SRT, 선점 우선순위, 다단계 큐(MQ), 다단계 피드백큐(MFQ)
- Multy Queue Scheduling
프로세스를 특정 그룹으로 분류할 수 있을 경우 그룹에 따라 각기 다른 준비단계 큐 사용
준비상태 큐 마다 다른 스켇줄링 기법 사용가능
다른 준비상태 큐로 이동불가
하위단계 준비
주기억장치관리
<li>단순관리</li>
<li>가상메모리</li>
보조기억장치를 주기억장치처럼 활용
파일관리
응용프로그램 운영체제 보조기억장치
파일 입출력 요청 파일 입출력 처리
* 파일시스템
unix - unix file system
linux - 확장 파일 시스템, ZFS, XFS...
mac os - HFS, HFS+...
(조각모음이 없다)
windows - FAT, NTFS
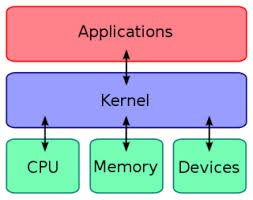
커널
applications, kernel, cpu/ memory/ devices
알고리즘
문제해결을 위한 절차/방법
ex) 테트리스를 잘 쌓으려면? - 옮긴다, 회전시킨다
ex) 여행가방을 꾸리려면? - 꺼내기 쉽게, 자주 쓰는 것, 부피에 맞게..
자료구조
한정된 공간에 자료를 효율적으로 이용할 수 있는 방법론
데이터를 구조적으로 표현하는 방식
ex)테트리스 - 빈틈이 안생기도록 옮기는게 알고리즘, 빈틈이 안생길만한 네모난 모양의 블럭으로 준비하는게 자료구조
ex)여행가방 - 가방에 맞게 짐(옷,충전기 등)을 규격화하는 것
원시구조
선형구조
배열
배열(신발장)은 데이터(학생)가 빠지더라도(전학) 배열을 줄이거나 늘릴 수 없다.
데이터를 설명하지 않아도 배열의 주소만 알면 찾아갈 수 있다.
연결리스트 (linked list)
단순 연결리스트 - 중간에 데이터가 빠지면 다음데이터에게 순서를 부여
- 배열을 메모리 공간상에 연속된 주소로 자원을 할당받음
- 링크드 리스트는 한 노드에 데이터와 주소가 있어서 각 노드가 서로 맞물려서 자료를 저장
- 배열은 접근속도가 빠르지만 삭제와 삽입의 작업이 번거로움 (새로 생성시켜서 통짜로 옮겨야 함)
- 링크드 리스트는 노드를 추가하거나 빼는 것이기 떄문에 노드의 삽입/삭제가 용이함
- 접근 속도는 느림 (첫 노드부터 원하는 노드까지 하나하나 거쳐가야 함)
- 희소행렬을 링크드 리스트로 표현하면 메모리가 절약된다고 함
※ 희소행렬? 행렬의 값이 대부분 0으로 되어 있는 행렬 (그와 반대되는 표현으로는 밀집행렬(dense matrix), 조밀행렬이 사용된다. 개념적으로 희소성은 시스템들이 약하게 연결된 것에 해당한다)

이중 연결리스트 - 다음데이터 뿐만 아니라 앞데이터에게도 순서를 부여

원형 연결리스트 - 마지막데이터와 처음데이터를 연결

ex) NSArray
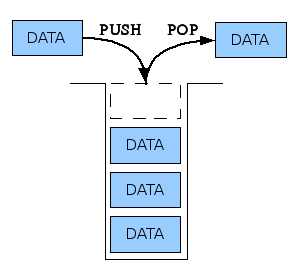
STACK
리스트의 한쪽 끝으로만 자료의 삽입 및 삭제가 이루어지는 자료구조
먼저 넣은 데이터를 나중에 꺼내는 방식 (LIFO)
서브 프로그램 호출시 복귀주소를 저장할 때
함수 호출 순서를 제어할 때
- 인터럽트가 발생하여 복귀주소를 저장할 때
- 후위표기법으로 산출된 산술식을 연산할 때
- 0 주소 지정방식 명령어의 자료 저장소
- 재귀 프로그램(Recursive Program)의 순서를 제어할 때
- 컴파일러를 이용한 언어 번역 시
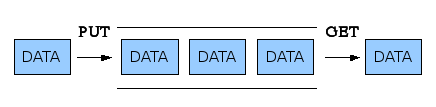
Queue
선형 리스트(Linear List)에서 한쪽에서는 삽입이 이루어지고 다른 쪽에서는 삭제가 이뤄지도록 구성한 자료구조
- FIFO방식으로 처리
순서를 기다리는 류의 프로세스 처리 예) 대기행렬
- 운영체제의 작업 스케줄링
Dequeue
- 삽입과 삭제가 양쪽 끝에서 모두 발생할 수 있는 자료구조
- Stack과 Queue의 장점만 따서 구성되어 있음
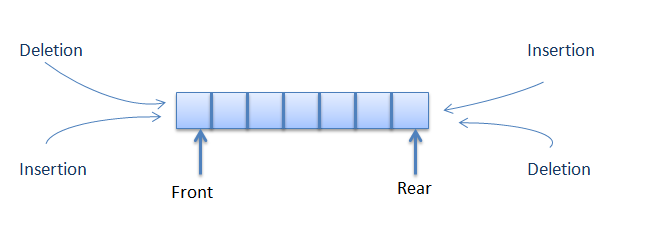
double-ended queue
TREE
- Node와 Branch를 이용하여 사이클을 이루지 않도록 구성한 Graph의 특수한 형태
- 족보, 연산 수식, 조직 구조도 등을 표현하기에 적합함
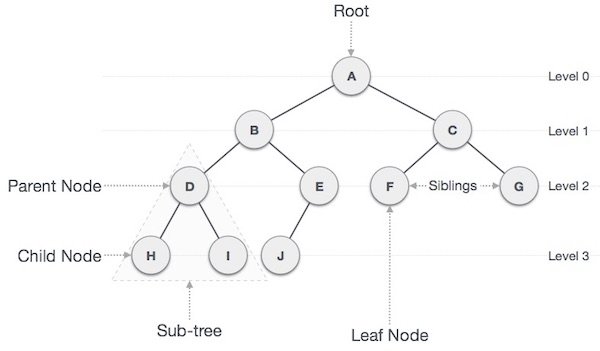
Graph
- 사이클이 있을 수 있는 정점(Vertex)과 간선(Edge)으로 이루어진 자료구조
- 사이클이 있을 수 있다는 것이 트리와 다름
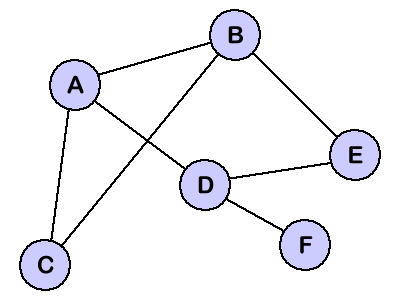
알고리즘
정렬 알고리즘
정렬 알고리즘 비교 영상
<li>선택정렬(selection) - 다 읽어들인 후 제일 작은 것부터</li>
<li>버블정렬(bubble) - 옆에 애랑 비교후 큰애를 뒤로</li>
<li>삽입정렬(insertion) - 두값을 비교해서 사이에 넣는 것</li>
<li>병합정렬(merge) - 구간을 나눠서 정렬 후 합치는 것</li>
<li>퀵정렬(quick) - 중간기준을 잡아서 반반 나눠서 크고 작은 것으로 구분. 평균적으로 가장 빠름. 기준을 잘못잡으면 항상 빠르진 않음</li>
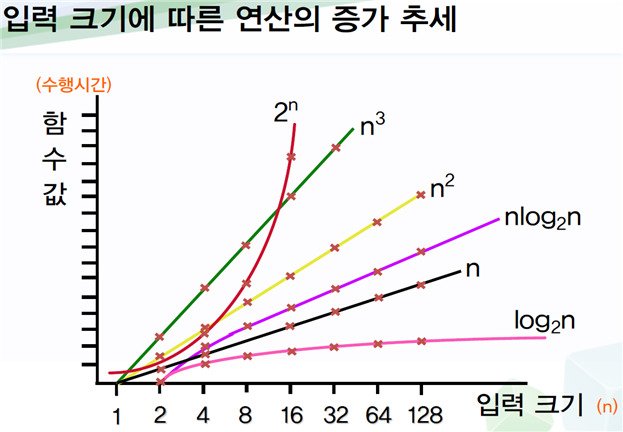
시간복잡도
<li>알고리즘이 실행되는데 걸리는 시간 분석</li>
<li>점근 표기법 (대문자 O표기법)</li>
정렬 알고리즘의 시간복잡도
선택 - O(n^2)
버블 - O(n^2)
삽입 - O(n^2)
병합 - (nlogn)
퀵 - (nlogn)
탐색 알고리즘의 시간복잡도
선형탐색 - O(n)
이진탐색 - O(logn)