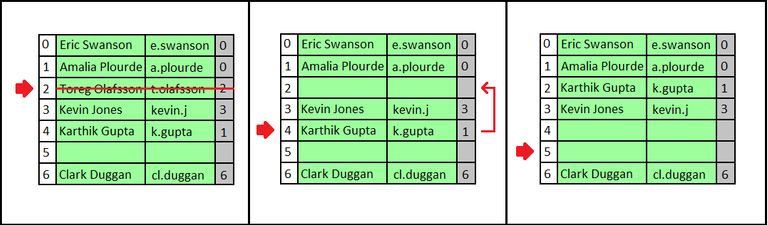
Bild Referenz: https://commons.wikimedia.org/wiki/File:Linear_Probing_Deletion.png
Intro
Hallo, ich bin's @drifter2! Der heutige Artikel ist an meinem englischen Artikel "C Hashtables with Linear Probing" basiert und wir werden über die anderen Methoden der Kollisionsauflösung reden. Die andere Methode (Verkettung) wurde beim vorherigen Artikel implementiert, zusammen mit der Theorie für Hashing und Hashtabellen. Ihr würde euch raten diesen vorherigen Artikel vor diesem Artikel zu lesen, damit ihr alles heute besser versteht. Also, fangen wir dann mal direkt mit der Implementation an.
Implementation vom Linearen Sondieren
Die Implementation von der Offenen Adressierung generell ist an Feldern-Arrays basiert. Die leichteste Methode von der Offenen Adressierung mit der wir Kollisionen beim Hashing auflösen ist das so genannte Lineare sondieren. Wie wir bereits beim letzen mal gesagt haben wird das neue Element damit bei der nächsten freien Stelle nach dem Hashing Schlüssel oder Index eingefügt.
Die Größe der Hashtabelle muss wieder mal eine Primzahl sein. Als Hash-Funktion werden wir die einfache Modulo-Funktion benutzen. Diese können ganz leicht mit "define" definiert werden, wie folgend:
#define N 53#define h(x) (x % m) //h(x) = x mod mDatenstruktur
Wie schon vorhin erwähnt wurde, wird die Datenstruktur ein Feld sein. Wir können diese Hashtabelle als einen Zeiger auf Ganzzahlen definieren (anstatt direkt als Statisches Feld von N Elementen) und danach mit "malloc" Speicher für diese Struktur zuweisen. Alle Elemente sollten danach als '-1' initialisiert werden, welches bei unseren Fall "leer" bedeuten wird. Das sieht in Code wie folgend aus:
int *table; // hashtabelleint i; // Loop Indextable = (int*)malloc(N*sizeof(int));// alle Elemente auf '-1' initialisieren (leer)for(i = 0; i < N; i++){ table[i] = -1;}Wie beim letzten mal wird der Code wieder mal ein Switch-Case-Menü sein. Gehen wir also mal in die Funktionen ein die wir bei dieser Hashtabelle ausführen können. Das eigentliche Programm wird nach der Beschreibung der Funktionen zusammen mit einer Beispiel-Ausführung zu finden sein. Fangen also dann mit der Beschreibung der Funktionen an...
Hashtabelle mit zufälligen Elementen füllen
Beim Einfügen von Elementen darf die Anzahl an Elementen mit denen wir das Feld befüllen nicht mehr als die freien-leeren Stellen des Feldes sein. Deswegen wird das nun wie folgend kontrolliert:
int num = 0; // Anzahl an Elementen die bereits eingefügt wurdeint n; // Anzahl an Elementen die wir einfügen wollendo{ printf("Lot to insert(<%d): ", N-num); scanf("%d", &n);}while(N - num < n); num += n;Danach werden wird eine Funktion zum einfügen n-zufälliger Elemente ausführen, wie folgend:
fill_array(table, N, n);Die eigentliche Implementation der Funktion sieht wie folgend aus:
void fill_array(int *A, int table_range, int number){ int i; int num; for(i=0; i<number; i++){ num = rand()%1000; // zufaellige Nummer von 0 bis 999 insert_table(A, table_range, num % table_range, num); }}Diese Funktion führt eine weitere Funktion aus, welche auch die Kollisionen auflösen wird. Beim einfügen wird jetzt also der richtige Index gefunden, wo wir vom eigentlichen Hash-Index anfangen und mit einem Rekursiven Algorithmus dann immer zu der nächsten Stelle gehen. Wenn eine freie Stelle gefunden wird, fügen wir das Element ein und dann hört die Rekursion auf.
Der Code dafür sieht wie folgend aus:
void insert_table(int *table, int table_range, int hash_index, int val){ if(table[hash_index] == -1 && hash_index < table_range){ table[hash_index] = val; return; } // Zum nächsten Index gehen indem wir den Wert mit Modulo // in Feld-Indexe konvertieren, somit kann man dann zirkulieren hash_index = (hash_index+1) % table_range; // wenn wir wieder beim ersten Index angelangt sind // heisst es dass die Hashtabelle bereits voll ist if(hash_index == val % table_range){ printf("Hashtable is full!\n"); return; } insert_table(table, table_range, hash_index, val); }Suche nach einem Element
Bei der Suche nach einem Element fangen wir beim eigentlichen Hash-Index an und suchen das komplette Feld. Es kann ja sein das ein Element des Clusters (Elemente mit selben Hash-Index) vorher gelöscht wurde. Das ganze sieht in Code wie folgend aus:
int search_table(int *table, int table_range, int val){ int i; i = val % table_range; do{ if(table[i] == val){ return i; } i = (i+1) % table_range; }while(i != val % table_range); return -1;}Löschen von Elementen
Beim Löschen von einem Element fangen wir beim eigentlichen Hash-Index an und führen die Such-Funktion aus, die wir bereits vorher implementiert haben. Wenn der Wert gefunden wurde wird das Element bei diesem Index dann gelöscht, dass geht sehr leicht indem wir den Wert auf '-1' setzen. Das sieht in Code wie folgend aus:
void delete(int *table, int table_range, int val){ int index; index = search_table(table, table_range, val); if(index == -1){ printf("Value %d doesn't exist on HashTable!\n", val); return; } table[index] = -1; printf("Value %d was found at table[%d] and was deleted!\n", val, index);}Hashtabelle ausdrucken
Das Ausdrucken von Elementen ist eine ganz leichte For-Schleife:
void print_table(int *table, int table_range){ int i; for(i=0;i<table_range;i++){ printf("%d ",table[i]); }}Ausführungsbeispiel
Den kompletten Code könnt ihr euch bei der folgenden Adresse runterladen:
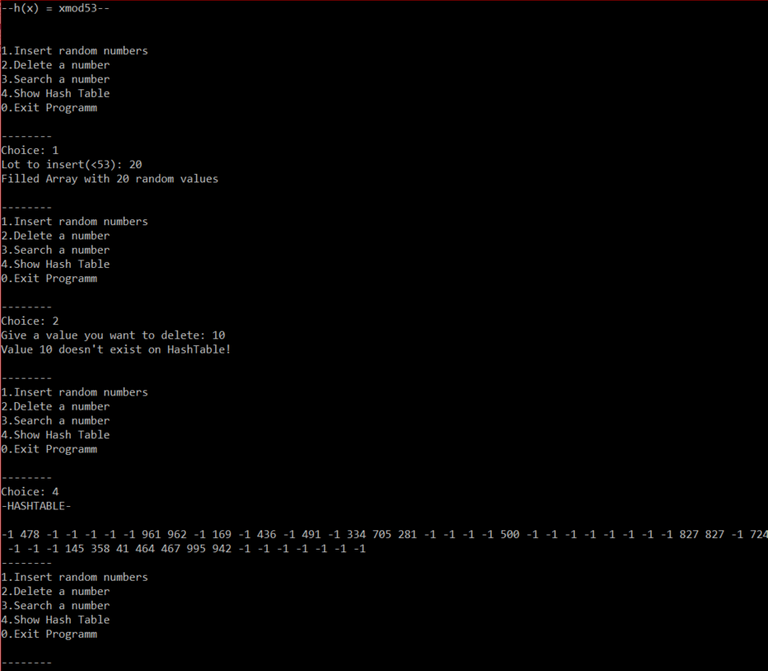
Eine Ausgabe kann z. B. wie folgend aussehen:
Die anderen Methoden
Bei den anderen Methoden müssen wir nun nur eine Code-Linie ändern, welche bei der Einfüge-Funktion ist. Diese ist:
hash_index = (hash_index+1) % table_range; Quadratisches sondieren
Das Quadratische Sondieren wird nun folgendes haben:
hash_index = ((hash_index) + i^2 ) % table_range; Die Funktion sieht wie folgend aus:
void insert_table(int *table, int table_range, int hash_index, int val, int i){ if(table[hash_index] == -1 && hash_index < table_range){ table[hash_index] = val; return; } hash_index = ((hash_index) + i^2 ) % table_range; if(hash_index == val % table_range){ printf("Hashtable is full!\n"); return; } insert_table(table, table_range, hash_index, val); }Doppel-Hashing
Doppel-Hashing ist noch einfacher. Hier müssen wir nun anstatt i^2 eine andere zweite Hash-Funktion benutzen. Dabei werden wir die selbe Hash-Funktion mit einer anderen "modulo"-Nummer 'H' benutzen, die wieder mal eine Primzahl sein sollte. Das sieht wie folgend aus:
hash_index = (hash_index + i*(val % H)) % table_range;Die ganze Funktion ist:
void insert_table(int *table, int table_range, int hash_index, int val, int i){ if(table[hash_index] == -1 && hash_index < table_range){ table[hash_index] = val; return; } hash_index = (hash_index + i*(val % H)) % table_range; if(hash_index == val % table_range){ printf("Hashtable is full!\n"); return; } insert_table(table, table_range, hash_index, val); }Referenzen:
- https://de.wikipedia.org/wiki/Hashtabelle#Algorithmen
- https://cg.informatik.uni-freiburg.de/course_notes/info2_11_hashverfahren.pdf
- https://steemit.com/programming/@drifter1/programming-c-hashtables-with-linear-probing
Der Artikel ist zu 90% eine Übersetzung von meinen englischen Artikel, aber enthält ein paar mehr Informationen. Die anderen Referenzen, haben dabei geholfen die richtigen Begriffe zu verwenden. Die eigentliche Änderung ist das ich nun jede Funktion erstmal alleine erkläre, und nicht direkt den ganzen Code gebe.
Vorherige Artikel
Grundlagen
Einführung -> Programmiersprachen, die Sprache C, Anfänger Programme
Felder -> Felder, Felder in C, Erweiterung des Anfänger Programms
Zeiger, Zeichenketten und Dateien -> Zeiger, Zeichenketten, Dateiverarbeitung, Beispielprogramm
Dynamische Speicherzuordnung -> Dynamischer Speicher, Speicherzuweisung in C, Beispielprogramm
Strukturen und Switch Case -> Switch Case Anweisung, Strukturen, Beispielprogramm
Funktionen und Variable-Gueltigkeitsbereich -> Funktionen, Variable Gueltigkeitsbereich
Datenstrukturen
Rekursive Algorithmen -> Rekursion, Rekursion in C, Algorithmen Beispiele
Verkettete Listen -> Datenstrukturen generell Verkettete Liste, Implementation in C (mit Operationen/Funktionen), komplettes Beispielprogramm
Binäre Suchbäume -> Baum Datenstruktur generell, Binärer Baum, Binärer Suchbaum, Implementation in C-Sprache (mit Operationen/Funktionen), komplettes Beispielprogramm
Warteschlangen implementiert mit Feldern -> Warteschlange als Datenstruktur, Implementation einer Warteschlange mit Feldern in C-Sprache, komplettes Beispielprogramm
Stapel implementiert mit Feldern -> Stapel als Datenstruktur, Implementation eines Stapels mit Feldern in C-Sprache, komplettes Beispielprogramm
Warteschlangen und Stapel implementiert mit Verketteten Listen -> Liste, Warteschlange und Stapel mit Liste implementieren in C-Sprache.
Fortgeschrittene Listen und Warteschlangen -> Doppelt verkettete Listen (mit Implementation), Zirkuläre Listen, Vorrangwarteschlange (mit Implementation)
Fortgeschrittene Bäume -> Βinärer Suchbaum (Zusammenfassung), AVL-Baum (mit Implementation), Rot-Schwarz (ohne Code) und 2-3-4 Bäume (ohne Code)
Stapel-Warteschlangen Übungsaufgabe mit Dynamischen Feldern -> Aufgabenbeschreibung, Lösung-Implementation in C (zutiefst) und Vollständiges Programm mit Ausführungsbeispiel
Stapel-Warteschlangen Übungsaufgabe mit Verketteten Listen -> Aufgabenbeschreibung, Lösung-Implementation in C (zutiefst) und Vollständiges Programm mit Ausführungsbeispiel
Hashtabellen Theorie und Implementation der Verkettung -> Hashtabellen Theorie, Implementation der Verkettung
Anderes
Funktionsvergleich mit Ausführungszeit und Berechnungen -> Ausführungszeit berechnen, Wie man etwas beim ausführen messt (generell), Vergleichsbeispiele
Schlusswort
Und das war's dann auch mit dem heutigen Artikel und ich hoffe euch hat dieser Artikel gefallen. Hiermit sind wir mit den eigentlichen Artikeln der C-Serie nun fertig. Kann sein das wir vom nächsten mal dann mit Java anfangen!


Keep on drifting! ;)
This post has been voted on by the SteemSTEM curation team and voting trail in collaboration with @curie.
If you appreciate the work we are doing then consider voting both projects for witness by selecting stem.witness and curie!
For additional information please join us on the SteemSTEM discord and to get to know the rest of the community!