As part of my mission to discover hidden gold in the Steemit stream, I have been writing tools to help sift the nuggets from the mud.
Turns out there are existing algorithms out there that can make life easier. One of which is "Readability Scoring".
What is a Readability Score?
There are tons of options, from USA "grade level" (eg. your content could be read by a Grade 5 student), through to highly complex math that is way over my head.
What I want is something that says essentially "This text would be easily read by half of the audience". It is just one filter out of many so does not need to be perfect.
Python to the rescue
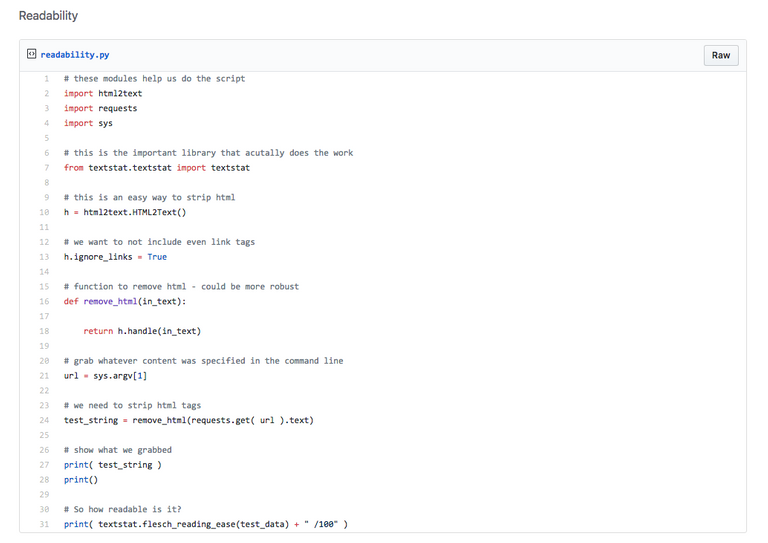
# these modules help us do the script
import html2text
import requests
import sys
First, we get the basic imports that will help us build the scaffolding to the script.
We need to:
specify the URL
load content from the specified URL
remove HTML from the web page that we load
Then we need to pass it through the function that will give us the readability score. That function lives in the textstat library:
# this is the important library that actually does the work
from textstat.textstat import textstat
Without stripping HTML we will confuse the function so we need to ensure even hyperlinks are removed:
# we want to not include even link tags
h.ignore_links = True
# function to remove html - could be more robust
def remove_html(in_text):
return h.handle(in_text)
For simplicity, I am specifying the URL via a command line argument for now. Later it will be part of my Discord bot.
We pass in the argument then grab it from the web using Requests.
# grab whatever content was specified in the command line
url = sys.argv[1]
# we need to strip html tags
test_string = remove_html(requests.get( url ).text)
# show what we grabbed
print( test_string )
print()
All that remains is to run it through the test!
# So how readable is it?
print( textstat.flesch_reading_ease(test_data) + " /100" )
Code
Code also available here:
Conclusion
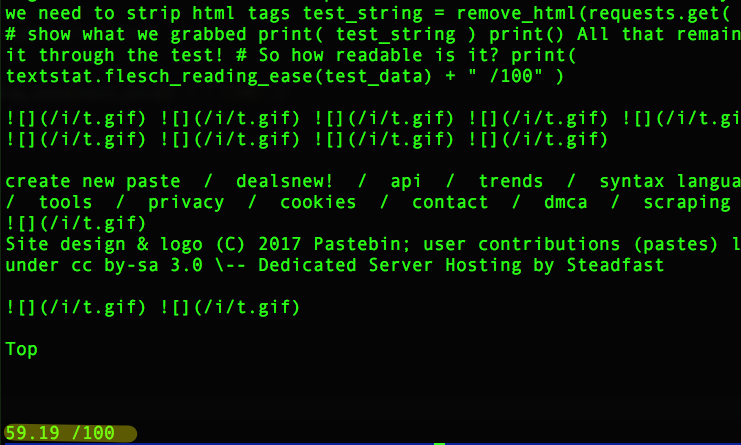
This article scored 59.19 / 100 ;)
That's too funny ;-)
I have a beginner question. How do you check Steemit posts? Are you copy past one url at a time, or you have automatized process and script can check last 50-100 posts? How would you go about it?
Good question, I'll write up my code for that too, but yeah I checked one post but then added so I could check a stream of them
Cool, looking forward to see that part of code ;-)
Interesting read. Thanks for sharing this.
Question: Would it be possible to alter the code so that I could do this on a local document instead of a url?
Yes, it would make it easier actually, you would just read the text file into a string:
with open('Path/to/file', 'r') as content_file: test_string = content_file.read()Thank you for your reply, much appreciated! My python foo isn't very strong, but I'll give it a go and try out. Would be cool to have the ability to test it locally before publishing, just for fun.
Here is the code for this
here.Congratulations, you were selected for a random upvote! Follow @resteemy and upvote this post to increase your chance of being upvoted again! Read more about @resteemy
That's interesting. Have you tried with other posts to see how they scored? Specially posts that you find easy and hard to read
I am getting a steady stream of them, it seems pretty accurate - the weird thing is the best-scoring turned out to be plagiarised (I flagged it)
If you believe this post is spam or abuse, please report it to our DiscordYou got a 27.78% upvote from @ipromote courtesy of @makerhacks! #abuse channel.
If you want to support our Curation Digest or our Spam & Abuse prevention efforts, please vote @themarkymark as witness.
You got a 75.00% upvote from @upboater courtesy of @makerhacks!