안녕하세요?
새로 스팀잇에 진입한 샘이입니다. 앞으로 과학기술과 미디어 분야에서 범과학, 콘텐츠 관련 추천 알고리즘, 블록체인, 이들에 대한 애플리케이션, 사회적 논의 등에 대해 폭넓게 다루겠습니다. 많은 관심 부탁드려요! 첫번째 시리즈는 스탠포드 텍스트를 기본으로 추천 시스템을 소화하며 작성해 보았습니다.
협업 필터링
협업 필터링(CF, Collaborative Filtering)과 협업 필터링을 활용한 각종 기법은 현재 추천 알고리즘에서 가장 보편적으로 쓰이고 있습니다. 데이터 과학을 시작할 때 쉽게 접하는 영화평점 데이터를 활용한 개인별 영화추천 시스템에도 협업 필터링이 쓰이지요. 우리가 어떤 것을 사용자에게 추천할 때, 가장 합리적인 방법은 우선 비슷한 관심사의 사람들을 찾고, 행동을 분석하여, 같은 상품을 추천해 주는 것입니다. 혹은 사용자가 이전에 구입한 상품과 비슷한 것을 추천하는 것도 또다른 방법입니다.
협업 필터링에는 대표적으로 사용자 기반(user-based) 협업 필터링과 아이템 기반(item-based) 협업 필터링이 있습니다. 협업 필터링을 이용한 각각의 사례는 다음의 두 단계를 따릅니다.
사용자 기반 협업 필터링 --> 데이터가 적고 변경이 자주 일어나는 경우, 실시간으로 유사도를 계산.
- 각 사용자에 대해, 아이템별 선호도(ex. 영화 평점)를 조사한다.
- 각 사용자 사이의 유사도(ex. 사용자-평점 matrix에서 코사인거리, 유클리디안거리, 피어슨상관계수 등)를 계산한다.
- 가장 유사한 사람이 가장 선호하는 아이템을 추천한다 / 추천가능한 아이템에 대하여 모든 사용자의 선호도 합으로 나누어 정규화한 뒤 추천한다.
아이템 기반 협업 필터링 --> 데이터가 방대하고 변경이 자주 일어나지 않는 경우. 유사도를 저장하여 사용.
- 각 아이템별 사용자의 선호도를 조사한다.
- 아이템별 유사도를 계산하고 저장한다.
- 추천가능한 아이템 중 가장 유사한 아이템을 추천한다.
추천을 위한 행렬 분해
다음으로 살펴볼 방법은 행렬 분해(Matrix Decomposition)입니다. 이 방법을 사용하면 행과 열에 어떤 아이템이 남아야 하는지 고민할 필요가 없어 매우 유용합니다. u라는 벡터를 사용자의 선호도, v라는 벡터를 영화와 관련된 파라미터로 정의해 봅시다.
이런 경우 i번째 사용자부터 j번째 영화까지 추천 등급인 xij를를 u와 v의 내적으로 근사할 수 있습니다. 이미 알고있는 사용자 유사도와 선호도 점수로부터 아직 모르는 추천 등급을 예측할 수 있습니다.
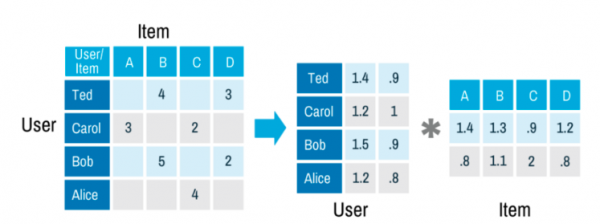
그림의 출처는 이곳입니다. 예시입니다. User와 Item 벡터곱으로 Ted가 아직 보지 않은 A아이템을 2.68만큼 선호할 것이라는 예측을 할 수 있습니다.
군집화(Clustering)
이전까지 다뤄본 방법들은 지도학습(Supervised Learning)에 해당하는 문제로 대체로 단순한 시스템에서 적용될 수 있습니다. 그렇다면 비지도학습을 추천시스템에 적용하면 어떻게 될까요? 만약 아주 큰 추천 시스템을 기획중일 때 가장 먼저 고려할 방법은 군집화(Clustering)입니다. 이전 사용자의 평점과 같은 정보가 충분하지 않는 상황이라면요.
데이터가 너무 많다면, 협업 필터링을 하기 앞서 군집화를 통해서 관련 사용자 이웃을 줄이는 방법입니다. 군집화를 통해 유사한 사용자 그룹(클러스터)을 만들고 클러스터 레벨에서 연산된 아이템을 추천받게 됩니다.
이후엔 각 방법에 대한 동작 및 구현에 대한 자세한 내용을 포스팅하도록 하겠습니다.
Reference
콘텐츠가 굉장히 전문가 뿜뿜입니다. 앞으로 기대 많이 하겠습니다. 웰컴투스티밋 !!