추천 시스템에는 콘텐트 기반 추천 시스템과 협업필터링 시스템이 있습니다. 이번 장에서는 콘텐트 기반 추천 시스템을 다뤄보도록 하겠습니다. 잠시 되새겨 보면, 콘텐트 기반 추천 시스템은 아이템별 속성을 토대로 유사성을 측정하는 방법이고, 협업 필터링은 사용자와 아이템 사이의 관계를 선호도 행렬로 접근하는 방식입니다.
아이템 프로파일
콘텐트 기반 추천 시스템에서는 각 아이템마다 프로파일을 작성해야합니다. 프로파일은 아이템에 관련된 중요한 특성을 가리킵니다. 예를들어 영화의 경우, 출연 배우, 감독, 제작연도, 장르와 같은 속성이 있습니다(단, 장르는 주관적인 영역이라 사람이 정하여 입력하기보다 후에 기계적으로 할당하기도 합니다). 물론 이외에도 여러가지 다른 속성이 있을 수 있지요.
문서에서 특성(키워드) 추출하기
물론 공급자나 제작자로부터 여러가지 특성 정보를 명시적으로 입력받을 수도 있습니다. 하지만 어떤 텍스트를 통해서 명백히 드러나지 않는 특성을 뽑아내야하는 경우도 있습니다. 흔히 ‘비슷한 문서’란 연달아 비슷한 단어가 배열되는 것을 의미하지만 추천 시스템에서는 다릅니다. ‘핵심’ 단어가 얼마나 ‘많이’ 함께 등장하는 지가 중요합니다. 가장 흔한 방법으로는 텍스트 마이닝 방법 중 TF-IDF를 활용하는 방법입니다.
stop word를 제거합니다. 자연어 문장 내에서 많이 쓰이지만 전혀 키워드로 쓸모없는, 영어의 The, is 등과 같은 단어이고, 한국어에서는 이, 그 등과 같은 단어가 해당될 것입니다. stop word는 구글링을 하면 쉽게 찾을 수 있습니다. 영어 stop word는 여기, 한국어 stop word는 여기에서 찾을 수 있습니다. 파이썬 패키지 중에 stop words를 포함하는 것도 있으니 쉽게 사용할 수 있을 것입니다. 하지만 분야별 특징이 있을 수 있으므로 반드시 stop word를 제거하시고 남은 단어들을 눈으로 확인해 보시길 바랍니다.
이어서, TF-IDF를 계산합니다. TF-IDF(Term Frequency – Inverse Document Frequency)는 여러 문서의 집합에서 어떤 단어가 어떤 문서에서 얼마나 중요한지를 나타내 주는 식입니다. TF는 한 문서 내에서 어떤 단어가 나타나는 빈도이고, IDF는 어떤 단어가 나타나는 문서 빈도의 역수를 가리킵니다. TF와 IDF값을 곱해 TF-IDF값을 얻어냅니다. 불리언값을 주거나 로그를 이용한 여러가지 수식이 있는데 한글 위키에도 자세한 내용이 있으니 참조합니다.
그리고, 적절한 threshold값을 주고, 이 이상의 높은 TF-IDF값을 갖는 단어를 뽑아냅니다.
이런 과정을 거치면 문서는 중요한 단어의 집합으로 표현됩니다.
문서간 유사성 계산하기
이제 집합 간 유사성을 계산하는 문제로 치환됐습니다. 몇가지 계산법이 있습니다. 자카드 거리(Jaccard distance)를 계산하거나, 코사인 거리(Cosine distance)를 계산하는 방법입니다. 벡터 공간상 거리 계산에 대해서는 여러 가지 다른 방법을 찾을 수도 있을 것입니다. 자카드 거리는 자카드 인덱스 J(A, B)를 구한 뒤, 전체 집합 1에서 빼는 방법입니다.
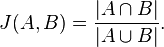
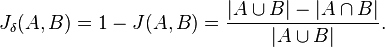
코사인 거리는 단어의 집합으로 표현된 문서를, 집합이 아니라 벡터로 간주하고 벡터상 거리를 구하는 방법입니다. 코사인 내적을 구하는 식에서 코사인 유사도 similarity를 구한 뒤 마찬가지로 전체 집합 1에서 빼게 됩니다.
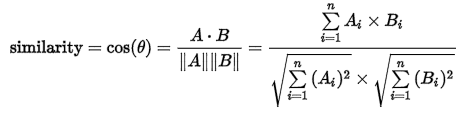
문서의 유사성을 구하는 방법으로 어휘기반으로 shingling, min-hashing, LSH 등이 비슷하게 있는 데, 나중에 다뤄보도록 합니다.
태그로부터 특성 추출하기(라기보다는 적용하기)
사용자로부터 문서나 이미지의 태그를 직접 입력받는 방법도 아이템의 특성을 정의하는데 유용한 방법입니다.
아이템 프로파일(벡터)의 표현
이제부터 콘텐트 기반 추천 시스템의 핵심을 구성하는 아이템 프로파일의 표현법을 알아보겠습니다. 아이템별 특성-값의 쌍으로 구성되는 벡터를 만드는 과정이라고 보시면 됩니다. 공급자나 제작자로부터 얻어서 쉽게 얻는 정보나 문서로부터 높은 TF-IDF값을 같는 키워드들이 등장하는 벡터를 구성할 수 있습니다.
예를 들어 각각 5명의 배우가 출연하는 A와 B영화를 가정해 봅시다. 만약 2명의 배우가 A와 B 모두에 출연했다면 영화배우의 수는 a, b, c, d, e, f, g, h로 8명일 것입니다. 이럴경우

이렇게 아이템 프로파일을 구성할 수 있습니다. b와 f 배우가 두 영화 모두에 등장하는 것을 알 수 있습니다. 한편, 각 영화에 3점, 4점이라는 평점이 있다고 가정할 수도 있습니다. 그런 경우엔

위와 같이 ‘스케일링 팩터’를 이용하면 됩니다. 0과 1이 대부분인 벡터에서 3과 4가 그값 그대로 작용된다면, 코사인값을 계산할 때 평점이 배우에 대한 점수보다 훨씬 중요하게 작용하게 되므로 조절하는 것입니다.
위 벡터 A와 B에 대한 코사인 값을 구해보겠습니다. 위에서 similarity로 제시된 식에 따르면
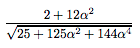
이렇게 주어지고,위 값은 코사인 값으로 값의 범위는 -1에서 1이며, 알파 값에 따라 아주 다른 값이 등장하게 됩니다. 어떤 알파값이 적당하다고 판단하기는 당장은 어려우나 확실한 건 의사결정에 중요한 역할을 한다는 것입니다.
다음 문서에서는 사용자 프로파일을 작성하고 사용자별로 아이템을 추천해 결과적으로 콘텐트 기반 추천시스템이 작동하는 방법을 알아보겠습니다.
Reference
어렵네요... ㄷㄷ