- Even quality code with good test coverage can benefit from fuzz testing!
- The Ripple blockchain server (
rippled) did not exhibit any security holes in its JSON implementation, or any invariant violations in itsLedgerTrieclass - However, the “stress” unit test of LedgerTrie omits a couple branches that were exercised by a fuzzed version of the same test.
Introduction

Ripple, the blockchain underlying the XRP cryptocurrency, positions itself as a tool for banks and payment processors. The security requirements for such a use case are high, and we are pleased to see that Ripple’s open-source implementation follows many best practices and uses mature components. For example, IPC is performed using the Google protobuf library, so we did not bother investigating that portion of the code. The origin of the JSON parsing library used in Ripple is not clear, but fuzz testing showed no errors.
We wanted to dig deeper than the protocol layers and so looked at the various unit tests implemented as part of the Ripple code. We found a randomized test, and it is generally simple to convert a randomized test into one which takes its random bits from a fuzzer instead.
LedgerTrie original test and modifications
The LedgerTrie is a data structure used to store information about competing versions of the blockchain ledger. For convenience, the unit tests have utilities which turn a string into a sequence of transactions suitable for use in the trie structure; the string “abcd” represents a sequence of four transactions. (If a transaction is present, it must follow the same set of transactions every time, but may be followed by different transactions when different parties disagree.)
The following randomized test uses a fixed schema for the entries in the trie: a regular tree with a branching factor of four. An entry is selected at random from these four-character strings, converted to the corresponding ledger history, and then added or removed from the LedgerTrie. After each step, a consistency check is run.
void
testStress()
{
using namespace csf;
LedgerTrie<Ledger> t;
LedgerHistoryHelper h;
// Test quasi-randomly add/remove supporting for different ledgers
// from a branching history.
// Ledgers have sequence 1,2,3,4
std::uint32_t const depth = 4;
// Each ledger has 4 possible children
std::uint32_t const width = 4;
std::uint32_t const iterations = 10000;
// Use explicit seed to have same results for CI
std::mt19937 gen{ 42 };
std::uniform_int_distribution<> depthDist(0, depth-1);
std::uniform_int_distribution<> widthDist(0, width-1);
std::uniform_int_distribution<> flip(0, 1);
for(std::uint32_t i = 0; i < iterations; ++i)
{
// pick a random ledger history
std::string curr = "";
char depth = depthDist(gen);
char offset = 0;
for(char d = 0; d < depth; ++d)
{
char a = offset + widthDist(gen);
curr += a;
offset = (a + 1) * width;
}
// 50-50 to add remove
if(flip(gen) == 0)
t.insert(h[curr]);
else
t.remove(h[curr]);
if(!BEAST_EXPECT(t.checkInvariants()))
return;
}
}
To create a version of this test that takes its input from a fuzzer instead of a random-number generator, we replaced all the calls to std::uniform_int_distribution with a function which read bits from standard input instead. Fortunately, no more than 8 bits were needed at a time, so a single function suffices:
int getBits( int max ) {
unsigned char c = 0;
std::cin >> c;
return c % max;
}
In addition, the loop terminates when end of file is reached, rather than a fixed number of iterations:
while (!std::cin.eof() )
{
// pick a random ledger history
std::string curr = "";
char depth = getBits( maxDepth );
char offset = 0;
for(char d = 0; d < depth; ++d)
{
char a = offset + getBits( maxWidth );
curr += a;
offset = (a + 1) * maxWidth;
}
// 50-50 to add remove
if(getBits(2) == 0)
t.insert(h[curr]);
else
t.remove(h[curr]);
assert( t.checkInvariants() );
}
The unit test can now be compiled and run with American Fuzzy Lop, a standard fuzz-testing utility. (This particular module was easy to extract from the larger rippled build, because the LedgerTrie implementation is a template and so resides mainly in a single header file.)
We also experimented with allowing the fuzzer to specify the structure of the test entries as well as the order in which they are added or removed, but this turned out not to have any advantage in block-level code coverage.
Measuring coverage
Fuzz-testing did not fail checkInvariants(), but produced a corpus of test inputs that thoroughly exercised the original code. We decided to look for cases where the original “testStress” failed to run some basic block, and the fuzzed version did.
Both versions of the test were compiled with GCC’s coverage build flags. Then we ran the original test once (note that its random seed is fixed) and the modified test against each of the inputs produced by AFL. This showed two branches missed by the original stress test. The output from gcov is shown below, with line numbers from LedgerTrie.h (https://github.com/ripple/rippled/blob/develop/src/ripple/consensus/LedgerTrie.h)
Original test:
Source code permalink: https://github.com/ripple/rippled/blob/dfb45baa93783cb9c16e50f36ae02be96af2cdb7/src/ripple/consensus/LedgerTrie.h#L464
17: 464: for(std::unique_ptr<Node> & child : newNode->children)
17: 464-block 0
call 0 returned 100%
call 1 returned 100%
call 2 returned 100%
17: 464-block 1
call 3 returned 100%
branch 4 taken 0% (fallthrough)
branch 5 taken 100%
$$$$$: 464-block 2
call 6 never executed
call 7 never executed
#####: 465: child->parent = newNode.get();
call 0 never executed
call 1 never executed
-: 466:
Fuzzed test:
10153: 464: for(std::unique_ptr<Node> & child : newNode->children)
8237: 464-block 0
call 0 returned 100%
call 1 returned 100%
call 2 returned 100%
10153: 464-block 1
call 3 returned 100%
branch 4 taken 19% (fallthrough)
branch 5 taken 81%
1916: 464-block 2
call 6 returned 100%
call 7 returned 100%
1916: 465: child->parent = newNode.get();
call 0 returned 100%
call 1 returned 100%
Original test:
Source code permalink: https://github.com/ripple/rippled/blob/dfb45baa93783cb9c16e50f36ae02be96af2cdb7/src/ripple/consensus/LedgerTrie.h#L528
3212: 528: if(it->second == 0)
call 0 returned 100%
branch 1 taken 0% (fallthrough)
branch 2 taken 100%
#####: 529: seqSupport.erase(it->first);
$$$$$: 529-block 0
call 0 never executed
call 1 never executed
branch 2 never executed
branch 3 never executed
Fuzzed test:
19926: 528: if(it->second == 0)
call 0 returned 100%
branch 1 taken 19% (fallthrough)
branch 2 taken 81%
3857: 529: seqSupport.erase(it->first);
3857: 529-block 0
call 0 returned 100%
call 1 returned 100%
branch 2 taken 100% (fallthrough)
branch 3 taken 0% (throw)
Analysis
Both of the missed branches may be covered by other unit tests in the same test suite; however, they show that the randomized test misses some of the possible paths of execution.
The first case requires a particular branch of the trie to be reduced to zero “support” (zero ledgers containing the necessary transactions.) The second case requires splitting a label in such a way that the label already has multiple children, for example
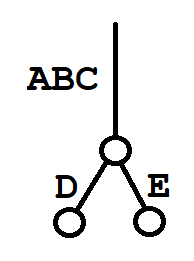
becomes
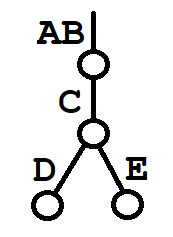
It is not too surprising that stressTest missed both these cases, even running thousands of inserts and deletes. Both cases are hard to hit from the “average” cases produced by the outcome of a large numbers of inserts and deletes, which are unlikely to exactly balance out. For example, deleting an internal node requires all four possible children to be absent Looking at the coverage numbers above, we see that the stress test only hit the branch at line 464 a total of 17 times out of the 10,000 inserts and removes performed.
Random selection of test cases, or one large randomized test case, rarely exercise all edge cases in a reasonable amount of time, though they are stil a valuable tool:

(Source: ~~~ embed:1080248432017788929) twitter metadata:dmFubGlnaHRseXx8aHR0cHM6Ly90d2l0dGVyLmNvbS92YW5saWdodGx5L3N0YXR1cy8xMDgwMjQ4NDMyMDE3Nzg4OTI5KXw= ~~~
A coverage-guided tool like a fuzzer can more efficiently search for inputs that use a branch not yet taken. A fuzzer can also generate a repeatable set of tests with better coverage than the particular random values chosen by a fixed seed.
We would encourage developers who have already gone to the effort of writing a randomized test to subject it to fuzz testing to get a sense of how good the coverage can be, compared to what their current randomization actually delivers. Although in this case no bug was found, we have performed similar transformations on other randomized tests that did expose failures, which we will discuss in future articles. We believe the construction of a tool to automatically perform this transformation is feasible; please let us know in the comments below if you would be interested in trying out this application of fuzzing on your own code.

Fuzz.ai
Fuzz.ai is an early-stage startup dedicated to making software correctness tools easier to use. Fuzzers, model checkers, and property-based testing can make software more robust, expose security vulnerabilities, and speed development.