
Cada día es mayor el aumento de datos disponibles, ya sean de ámbito profesional o simplemente en lo social. Todo esto gracias a la era de la computación y el internet.
Pero, ¿qué quiero decir con todo esto? Te colocaré un ejemplo sencillo: Imagina que tienes un pequeño negocio de ropa y mensualmente realizas una encuesta a tus clientes, intentando saber qué es lo que más les gusta o les puede llegar a gustar. Al cabo de dos años te expandiste e inauguraste algunas franquicias alrededor de la ciudad. Notas que ya no es tan fácil, ahora tienes más clientes. Además de eso, ahora quieres saber el peso estándar de tus clientes. Pero sigues creciendo en fama y ahora tienes franquicias por todo el mundo. ¿Cómo harás para recolectar toda esa información y para saber si tus ingresos tienen relación con algún producto en específico?
Es justo aquí donde entra el Data Science y el Machine Learning.
¿Qué es un Data Scientist?
Es un profesional con formación en análisis de grandes cantidades de datos, aplicando diferentes métodos matemáticos, entre ellos estadísticos y con gran conocimiento en lenguajes de programación.
Bien, ya tenemos claro lo que hace un Data Scientist, pero ahora tenemos otra duda: ¿Qué es Machine Learning? Me imagino que piensas que jamás has escuchado nada de eso o que jamás lo has visto. Pues te equivocas, estás más familiarizado con esto de lo que crees.
Uno de los reproductores de música online más conocido y utilizados es Spotify. Es sencillo de usar, puedes escuchar la música que te guste en cualquier sitio y no ocupas espacio en tu disco duro. Personalmente, una de las funciones que me gusta más de Spotify es que me recomienda otras bandas y géneros en base a los que ya escucho y me gustan. Suena genial, ¿verdad? Pues esto es Machine Learning.
Guarda toda esa información de bandas que te gustan o los géneros que más escuchas y, por supuesto, también aquellos que te recomendó y no te gustaron. Todo esto es almacenado en una base de datos para ser utilizado a futuro. Muy parecido a las encuestas a tus clientes en la tienda de ropa.

Después de toda esta introducción intentaré mostrarles de la manera más sencilla que pueda cómo funciona.
El perfil de un Data scientist tiene gran similitud con el de un Astrofísico. En la Astrofísica, y gracias a los nuevos telescopios, se cuenta con gran cantidad de información de estrellas o cualquier otro evento astronómico. Sería prácticamente imposible tratar con todo esto de manera manual. Es por esto que se utilizan lenguajes de programación como Python o Fortran para hacerlo de manera eficiente.
En el trabajo de investigación que estoy realizando para optar por el título de Licenciada en Física, trabajo con una muestra de 189 estrellas. Uno de los primeros retos con los que me topé al empezar mi investigación fue el de juntar dos listas diferentes o arreglos con informaciones de 989 estrellas. Pues bien, realicé un programa en Fortran que me facilitara las cosas.
Te mostraré el código y te explicaré de la mejor manera cómo funciona:
implicit double precision (a-h,o-z)
c Este programa toma dos arreglos y los combina en un único arreglo
dimension nestrella1(1000),ew(1000,18),nestrella2(1000),
* lspt(1000),bv1(1000),am1(1000),feh1(1000),bv2(1000),am2(1000),
* feh2(1000)
c*****************************************************************************
i=1
open(7,file='fort.20',status='old') !Lectura de datos
1 read(7,*,end=10)nestrella1(i),(ew(i,j),j=1,18)
i=i+1
goto 1
10 close(7)
il1=i-1
print*,il1
c******************************************************************************
i=1
open(30,file='parametrosfisicos',status='old') !Lectura de datos
2 read(30,*,end=20,err=1)nestrella2(i),lspt(i),bv1(i),am1(i),feh1(i)
i=i+1
goto 2
20 close(30)
il2=i-1
print*,il2
c******************************************************************************
do i=1,il2
if (nestrella1(i).eq.nestrella2(i))then
write(15,100)nestrella2(i),(ew(i,j),j=1,18),lspt(i),bv1(i),
* am1(i),feh1(i)
100 format(i6,18f6.2,1x,i4,f7.2,f7.2,f7.2)
endif
enddo
do i=1,il2
if(lspt(i).ge.30.and.lspt(i).lt.40)then
write(16,200)nestrella1(i),(ew(i,j),j=1,18),lspt(i),bv1(i),
* am1(i),feh1(i)
200 format(i6,18f6.2,1x,i4,f7.2,f7.2,f7.2)
endif
enddo
end
La primera línea de código establece simplemente el nombre del programa, mientras que la segunda define el tipo de variables que se utilizarán en el programa. Para este caso en particular, todas las variables serán implícitas de doble precisión, y se pueden entender de la siguiente manera: Aquellas cuyo nombre comiencen con las letras de la a-h o de la o-z, serán del tipo real, mientras que las que comiencen con las letras de la i-n serán del tipo entero. Por ejemplo, en el código se tiene que i=1, por lo tanto se considerara entero.
Los arreglos pueden ser tratados simplemente como matrices utilizando la instrucción dimensión, definiendo el nombre de la variable y entre paréntesis sus dimensiones en i y j. En el caso de ew(1000,18), esta tendrá mil filas y dieciocho columnas.
La instrucción ‘open’ abre la lista o arreglo donde se encuentran todos los datos, y la instrucción ‘read’ se encarga de leerlos y colocarles un nombre determinado por el cual serán reconocidos a lo largo del código, por ejemplo:
fort.20 está conformado por diecinueve columnas, donde a la primera columna se le da el nombre de nestrella1(i) y a las dieciocho restantes el de (ew(i,j),j=1,18).
Se debe utilizar ‘goto’ para que lea cada unos de los datos dentro del arreglo. Tambien se utiliza un contador para tener el valor total de datos, el cual es dado por la instrucción ‘print’, la cual se encarga de mostrarlo por pantalla.
i=1
i=i+1
il2=i-1
Donde al final se le resta uno, ya que el contador se inicializo en 1 y no en 0. Una vez terminados de leer cada uno de los datos, se cerrará la lectura con la instrucción ‘close’.
Una vez completada la lectura de los dos arreglos se procede a agregarle a fort.20 los valores dentro de parámetros físicos. Se debe dejar en claro que ambos arreglos deben tener la misma dimensión en el número de filas. En este caso ambos tienen 989 estrellas, utilizando como único valor en común el número HD de la estrella para lograr unir ambas listas. Esto se hace utilizando un condicional ‘if’ dentro de un ‘do’ (do i=1,il2 , en el que el loop irá desde la estrella número 1 hasta la estrella 989). De cumplirse la condición, éste guardará la combinación de ambos arreglos en un archivo llamado fort.15 y tendrá el formato establecido en:
100 format(i6,18f6.2,1x,i4,f7.2,f7.2,f7.2)
Donde esta instrucción establece el número de decimales que tendrán los valores en el archivo y el espacio entre las columnas.
En la investigación solo me interesa trabajar con estrellas tipo F, así que utilizo un segundo condicional para hacer un nuevo arreglo con ellas en base al de 989 estrellas, y finalmente termino con una muestra de 189 estrellas que se guardarán en un archivo llamado fort.16 y utilizo la instrucción ‘end’ para dar por terminado el programa.
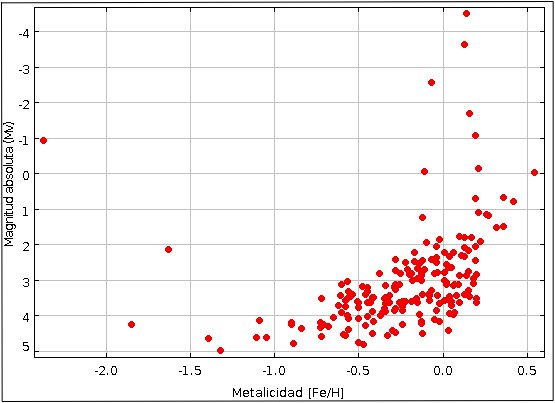
Ahora fácilmente puedo ver la relación de la magnitud absoluta de mi muestra de 189 estrellas con la metalicidad, tal y como se muestra en la figura 1.
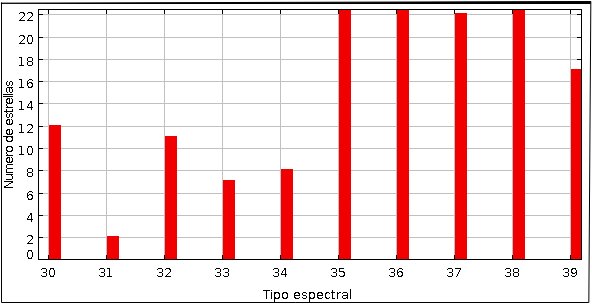
O por ejemplo realizar un histograma de frecuencias de la muestra según su tipo espectral, figura 2.
Como puedes ver, programar y tener un amplio conocimiento de métodos matemáticos facilita mucho las cosas. Así que es de crucial importancia entender el impacto que trae la “Big Data” y el Machine Learning a la investigación.
Hasta los momentos se dan cursos y talleres en estas ramas, pero sería muy útil que los diferentes institutos y universidades de índole científico las consideraran en sus diferentes programas académicos.
Referencias:
Ian D Chivers, Jane Sleightholme. Interactive Fortran 77 A Hands on Approach. Segunda edición. 1984
Colin Simpson, Thomas Robitaille. Computational Astrophysics. 2008
Links de interes:
Fortran 77 Tutorial Stanford University
Muchas gracias por leer mi humilde post, estaré atenta a sus preguntas o sugerencias en los comentarios.
Si desean estar al tanto de mi nuevo contenido, los invito a unirse a mi canal Bridareiven en Telegram.

La imagen anterior y el separador de texto fueron diseñados por mí, utilizando elementos de Pixabay y Flaticon.
La Figura 1 y 2 fueron diseñadas por mí utilizando el graficador TOPCAT (Tool for OPerations on Catalogues And Tables).
Bien explicado @bridareiven, felicitaciones. Te sigo
Muchas gracias!, me alegra que te gustara.
Peace, Abundance, and Liberty Network (PALnet) Discord Channel. It's a completely public and open space to all members of the Steemit community who voluntarily choose to be there.Congratulations! This post has been upvoted from the communal account, @minnowsupport, by Bridareiven from the Minnow Support Project. It's a witness project run by aggroed, ausbitbank, teamsteem, theprophet0, someguy123, neoxian, followbtcnews, and netuoso. The goal is to help Steemit grow by supporting Minnows. Please find us at the
If you would like to delegate to the Minnow Support Project you can do so by clicking on the following links: 50SP, 100SP, 250SP, 500SP, 1000SP, 5000SP.
Be sure to leave at least 50SP undelegated on your account.
Hola @bridareiven Saludos.
En lineas generales este es un muy buen post, presenta un contenido bien explicado, original, tu hiciste casi todas las imágenes y eso tiene su merito, el maquetado esta muy bueno y la redacción y ortografía me pareció excelente.
Como recomendación te diría que debes pensar bien en el mercado de lectores a quienes le diriges la información. En steemit hay muchos lectores de contenido interesante pero entretenido y noto que tu contenido es mas científico tecnológico, por lo que lo ideal es promocionarlo en servidores de este genero y de esa forma podrás obtener el éxito que merece este tipo de post.
Éxitos en tu blog.
@bridareiven you were flagged by a worthless gang of trolls, so, I gave you an upvote to counteract it! Enjoy!!