Apache Pulsar has become increasingly popular, especially since becoming a top level project in the Apache Software Foundation. One of the interesting things we’ve seen is that people are using Pulsar not only for pub/sub messaging, but are also taking advantage of Pulsar’s scalable storage architecture and tiered storage capability to store data streams in Pulsar. As a result, it is only natural for users to want to query what data they have stored in Pulsar. Also, some users would like to be able to query the data as it arrives and not have to wait for it to be moved to an external system like a database. This feedback led to the development of Pulsar SQL, a new framework making its debut in Apache Pulsar 2.2.0 that allows users to efficiently query data streams stored in Pulsar using a SQL interface.
In this blog, not only will we provide a technical overview of Pulsar SQL’s architecture, implementation, and performance, we will also discuss the background that led to the development of Pulsar SQL and the use cases for it.
Background
Apache Pulsar, originally developed as a next-generation pub/sub messaging system to address several shortcomings of existing messaging and streaming systems, has evolved to take on far more use cases than the traditional pub/sub messaging use case. Pulsar’s innovative two level architecture, that separates serving/compute from storage, allows users to easily scale out compute and storage resources independently of each other. Since that design makes it easy to add additional storage resources, users have started to use Pulsar not only as a pub/sub system but also as a storage platform to store all their streams old and new. With the addition of tiered storage to Pulsar, the usefulness of a “stream store” or “event store” has become even more relevant. With tiered storage, users can augment their existing Pulsar cluster with cloud storage (e.g. Amazon S3, Google Cloud Storage, etc.) to store a practically unlimited amount of streaming data in the cloud at very low per unit cost.
The ability to store and archive data streams within Pulsar together with the ability to handle streaming data makes it possible to access both real-time and historical data in a single system. That’s something that to date has required multiple systems and tools. With Apache Pulsar, you can access both in one system. The implementation of the schema registry and now the release of support for SQL querying provide an even easier way to take advantage of that.
Pulsar SQL is a query layer built on top of Apache Pulsar that enables users to dynamically query all streams, old and new, stored inside of Pulsar. Users can now unlock insights from querying both new and historical streams of data in a single system.
Another important use case for Pulsar SQL is that it can greatly simplify many data pipelines. In traditional ETL pipelines such as those used to feed data lakes, the data is extracted from a collection of external systems and run through a series of transformations to cleanse and format the data into the desired format before it is loaded into the target system. Typically these steps are executed as independent steps in a sequence, and a failure in any one of the steps halts the entire process. This approach suffers from two significant drawbacks:
Each of the ETL steps inevitably ends up being specifically engineered to the framework it runs on, e.g. Sqoop or Flume jobs to extract the data, Hive and Pig scripts to transform the data, and Hive or Impala processes to load the data into queryable tables.
This process is batch-oriented by nature, and thus the data loaded into the data lake is not kept consistent with the incoming data stream. The longer the interval between batches, the less timely the data, and by extension, the decisions made based on the data.
With Pulsar SQL, Apache Pulsar alleviates these two issues by allowing you to ingest, cleanse, transform, and query the data stream on the same system. Because Pulsar has a scalable storage layer (provided by Pulsar’s use of Apache BookKeeper as its event storage layer), Pulsar eliminates the need for two separate systems and treats all of your data–both streaming and historical–the same.
Pulsar SQL leverages Presto and Pulsar’s unique architecture to execute queries in a highly scalable fashion regardless of the number of topic partitions that make up the streams. We will discuss the architecture further in the following section.
Architecture
The integration between Pulsar and Presto is the Presto Pulsar connector that runs on Presto workers within a Presto cluster. With the connector, Presto workers can read data from a Pulsar cluster and execute a query on that data.
Now let’s talk about how the Presto Pulsar connector efficiently reads data from Pulsar. In Pulsar, producers write messages into Pulsar and these messages are organized into channels called topics. Topics in Pulsar are stored as segments in Apache Bookkeeper. Each topic segment is also replicated to a configurable (default 2) number of Bookkeeper nodes called Bookies.
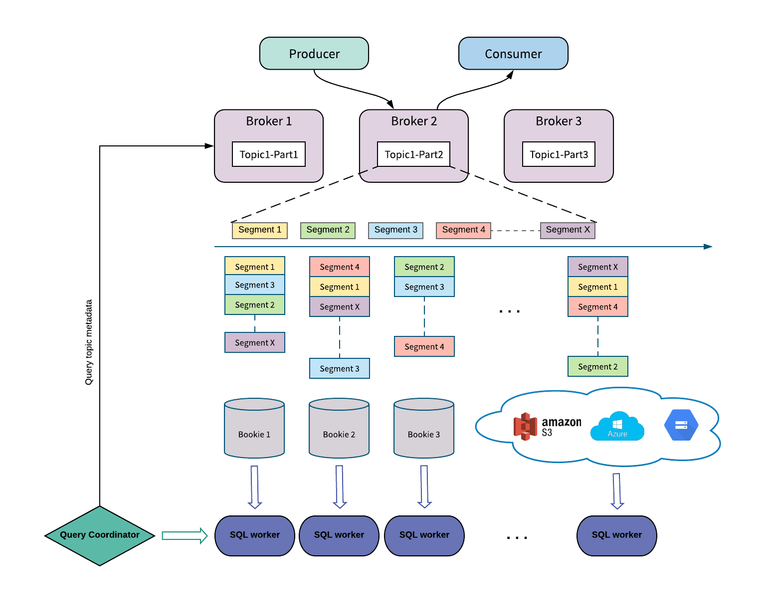
Pulsar SQL was designed to maximize data scan speed, thus the Presto Pulsar connector reads data directly from Bookies (not via Pulsar’s Consumer API) to take advantage of the Pulsar’s segment-based architecture. While the Consumer API is suitable for consuming messages in a pub/sub use case, it is not necessarily optimized for bulk reads. To maintain ordering, each topic in Pulsar is served by only one Broker, thus constraining the read throughput to be that of one Broker. To increase read throughput users could utilize partitioned topics, but Pulsar wants users to be able to query topics in a performant manner without having to modify existing topics. For the querying use case, we don’t really care about ordering, we just need to read all of the data. That makes it a better approach to read the segments that make up a topic directly. Since segments and their replicas are spread among multiple BookKeeper bookies, Presto workers can read segments concurrently from horizontally scalable number of BookKeeper nodes to achieve high throughput. To achieve higher read throughput, users can simply configure a topic to have a higher replica count.
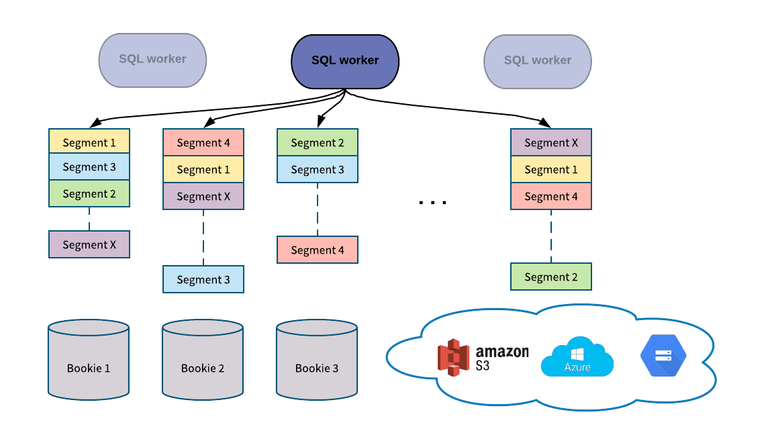
Not only can Pulsar SQL query data that resides in bookies, but also data that has been offloaded into cloud storage. With tiered storage, users can not only store more data than their physical cluster can actually handle, but also query that data to gain valuable insights.
Use Cases
We will now discuss some use cases for Pulsar SQL. We have listed below some popular use cases in which Pulsar SQL can be useful and help the users simplify their architecture. Traditionally, multiple systems would be needed to accomplish this task, but with the addition of Pulsar SQL, users can use Pulsar for both log ingestion and querying.
Real-Time Analytics: The ability to query data as soon as it is received by Pulsar makes it possible to run SQL queries that can incorporate the latest data for real-time dashboards and monitoring.
Web Analytics / Mobile App Analytics: Web and mobile applications generate streams of usage and interaction data that can be queried to detect usage patterns, improve applications, customize experiences, and more in real-time.
Event Logging and Analytics: Event logs from user applications or system logs from operational systems can be processed and stored by Pulsar. Pulsar SQL can then be used to query the stored logs stored to debug applications and search for failures.
Event Replay: Allows you to extract a series of events in the sequence they occurred using a SQL query. For example, consider the scenario in which you identify a spike in fraudulent transactions over a short period of time. You can capture these event streams and replay them to simulate the fraudulent activity as your data science team refines their fraud detection algorithms.
Sources : https://streaml.io/blog/querying-data-streams-with-apache-pulsar-sql
Source
Copying/Pasting full or partial texts without adding anything original is frowned upon by the community. Repeated copy/paste posts could be considered spam. Spam is discouraged by the community, and may result in action from the cheetah bot.
More information and tips on sharing content.
If you believe this comment is in error, please contact us in #disputes on Discord
✅ Enjoy the vote! For more amazing content, please follow @themadcurator for a chance to receive more free votes!
Hi! I am a robot. I just upvoted you! I found similar content that readers might be interested in:
https://streaml.io/blog/querying-data-streams-with-apache-pulsar-sql
Hello @sulist! This is a friendly reminder that you have 3000 Partiko Points unclaimed in your Partiko account!
Partiko is a fast and beautiful mobile app for Steem, and it’s the most popular Steem mobile app out there! Download Partiko using the link below and login using SteemConnect to claim your 3000 Partiko points! You can easily convert them into Steem token!
https://partiko.app/referral/partiko
Congratulations @sulist! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Vote for @Steemitboard as a witness to get one more award and increased upvotes!