API service to try and help solve some of the spam problems on Steem.Steem Sincerity is a project I post about under my @andybets account. It is an
One of its API functions allows you to query up to 100 accounts, and have the classification scores quickly returned.
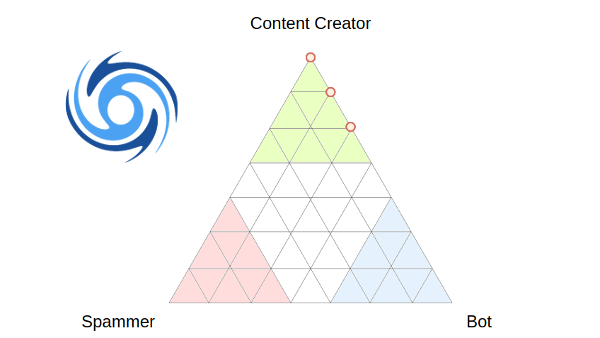
Each account is given a probability of being a:
- Content Creator - an account providing value to Steem through their posts and comments
- Spammer - an account posting mainly spam or very low-value content
- Bot - an account operated by software
As a pure API though, it's not directly very useful for most users, so I have added an interface to the SteemReports website so you can see this data presented in a graphical form.
The probabilities add up to 100%, so I use a Ternary Plot to show the relative likelyhood of accounts belonging to each class. You can add up to 100 accounts to the list, and any that has a record in the Sincerity database will be added to the chart. Hovering your mouse over each point will show the name(s) of the account(s).
Because of the algorithm currently used, there are only 36 possible positions on the chart that an account can appear, so some positions may contain several accounts.
Here is an example showing the current classifications of the top 20 witness accounts plus steemreports. A couple are missing because the witness accounts haven't posted anything recently.
Please note that classification is only as good as the Sincerity training data allows it to be, and I am working to collect much more data to improve classification in the coming weeks.
I would be happy to hear about any big misclassifications though, as they may give me information to help improve future results.
This is cool, and love the graph choice.
Is the code publicly available for the classification process?
Thanks.
No. I've been considering whether to open source it, and there are two issues:
I think this issue is similar to some we've discussed in the past, with no obvious perfect solutions.
Sure, and my position remains the same: I can't trust a metric I can't inspect, so while I know you have the best of intentions you become the point of trust for your algorithm instead of the algorithm standing objectively on it's own.
A compromise could be to allow someone you trust to inspect it, someone with some credibility publicly, and they can state their findings without revealing the algorithm. If you had a few of those from people I knew to be competent and honest it would significantly raise my trust in it.
Just something to think about in the interest of claiming these metrics have any meaning.
I suppose the community can look at the results from the algorithm to assess whether it has any meaning, and yes, trust me if they think I deserve it. That said, I wouldn't rule out what you have mentioned.
Perhaps you could send me a list of people you know to be competent and honest? ;)
The results won't be enough to test that unless you had good knowledge of the entire ecosystem, i.e. what did it leave out? Sounds expensive to verify blindly.
@timcliff seems to fit the bill, and I believe he's taken an interest in your project.
I'll certainly consider that once I have more training data and a cleaner implementation. That's not a very long list of people though, and you said you'd want 'a few' in order to significantly raise your trust.
It necessarily going to be a small list, I can only think of one other - @jesta. Think about it and why not pick some others too, it's not specifically for me or anything.
This is a really great tool @steemreports. Unfortunately, resteeming accounts not only pick content of value, but everything people pay them to resteem and this is really hurtful for my feed, because it hides my friend's content. So, I was trying this tool out and found that some of my steemit friends get a tiny bit in the direction of spammers, how do you determine that? Is there a correlation between posting frequency and spamming? Or maybe word length and spamming? I'm really curious to know. I love to play with these genius tools!
Thank you. Yes, posting frequency and word length are some of the many factors used in the algorithm. It is interesting, but I don't want to disclose too much as it might undermine the effectiveness of the process.
I haven't been recording resteems, but I now you mention it, I suspect that might be useful for this classification too!
Yeah, you are right, thanks for answering my intrusive questions anyway :). Yeah, that's it, maybe if the resteem to posts ratio in one account is 90/10 I would say it belongs in the spammer side of things, maybe I'm being to harsh...
Very good report. Love the ternary plot. Very effective also for determining difference between bad and good bots, and bad and good humans. Often people talk about the 'bot problem', but there are also many useful and good bots on the steem network, so their knee jerk reaction of "why can't we ban bots", fails to make that nuance.
Thanks. I'm undecided about bots in general, but they are certainly a factor which adds complexity to the Steem ecosystem.
This is so cool :) I would lik to use it for my voting bot to exclude spammers. But - does the verification tells more about user commens or posts? I mean does he create spammy posts or more spam comments?
Thanks. This classification tells us more about comment spam than spammy posts because that is currently more represented in the initial training set, and where I think it can have the greatest positive impact. I would think (but don't know) that spammy posts which are written deliberately to promote through vote bots will tend to be harder to classify with machine learning, due to more effort being made, and the plagiarism of good content.
Aye. Nevertheless, if someone produces spammy comments, his posts are probably also low value :)
Yes, that's true :)
What is your definition of being bot? Because this is a very important question :D
Good question.
I don't have any definitions. I have simply trained the initial classifier with a selection of bots that I manually evaluated as such. In arriving at classifications for the initial training set, my biases towards what I consider to be a spam and bots will inevitably shine through. This will be reduced over time as the training data expands.
I'll answer with my current opinions anyway though, insofar is they relate to this project :)
If someone creates normal content, but votes using script - is he bot? Depends on proportions.
If someone only votes (manually, within small period of time) - is he bot? No.
If someone only makes witness actions - is he bot? No, it doesn't affect comments/posts.
If someone posts the same comment in response to specific posts - is he bot or spammer? Depends on whether it's scripted.
It is good to frame the project better though, and maybe I haven't given enough thought to that.
i want to weigh the votes not on the vote wheight alone for my training data but also will try to filter out vote bots.Yep defintitley going to use it to for my voting bot. When i'm finished i should have something similar to @trufflepig (most likely not as good)
I really like this project of yours. Is it just you working on it?
The problem of spam and bots is a tough one. They can really screw up the economies of crytpos. Just getting a good training data set is tough.
It is a difficult problem. I think a good training set will go a long way in improving performance and I'm discussing collaboration on this. I'll hopefully have an announcement on that soon!
Perhaps some volunteers to manually classify posts in the training sets?