Can't read my
Can't read my
Noooo he can't reaaaad my
pooooker face
She is gonna let nobody
P p p poker face, p p p poker face
na na na na
Big love if you’ve read this with Cartman’s voice <3
Heeey Nikola, where have you been so long? I’ve read this with Cartman’s voice!
Then, big love for you bro<3
What’s uuup? Do you remember when we talked last time about AI and stealing the bike? Oh... I have... I have good news for you!
Oh, what kind of the news?
I gotta show you this... look at this, look... taaa daaaa.
Bro, is this your bicycle?
Yes, it’s not stolen!!!
I think that you don’t underst...
And look, I’ve tied it with four cables hahah, say how powerful developer I am!
You rock!
What are we going to learn today and why are you singing this Lady Gaga’s song?
Well... what do you think, could AI really read your poker face and beat you in the poker? Or maybe in chess, or checkers?
Hmmm let’s find out.

Maxpixel.net, Public domain CC0
Last time, we were talking about some uninformed search algorithms and I gave you small insight into how they work. Can we apply similar strategies to AI in order to learn it to play some games? And why would people spend time in a laboratory, trying to make some program which will play some board game? Aren’t we supposed to make AI which will do everyday stuff, talk with us, do some simple tasks, eventually conquer the world?
Games were always attractive to people from AI field, because they represent certain polygon where we can see how smart is our AI. Maybe some of you are familiar with the Game Theory which says that a game is actually one process of making decisions and basically, we can look on everything in our life like on a game, because we are supposed to always find out the best possible decision in every situation. So when our AI starts managing itself in some board game successfully, we could apply that maybe on some problems in the real world. Also, it’s easier to evaluate performance of the AI in a game environment, because it can either win or lose – it was successful or it wasn’t.
First game that computer was able to play, was the game of checkers. The man who developed that program was Arthur Samuel from IBM and that program was learning how to play checkers simply by playing against itself thousands of times. For just a few days, program succeeded to beat Samuel in this game and later in 1962 it won against the man who was “a blind checkers master”. If we consider that making this program was in 1950s and that technology at that moment was on a very low level comparing with today’s ( this program used magnetic tape as a memory!) we can say that this was one really big step in a computer science.
Checkers are nice, but there is one game that challenges and occupies people since its beginning – that’s right, chess. This game is interesting because it has so many tactics and possible moves that it represented the real challenge in the area of AI. You’ve probably heard about IBM’s famous computer called Deep Blue which won against Kasparov? Do you know how it did it?

Maxpixel.net, Public domain CC0
The truth is that it wasn’t quite fair battle, because Deep Blue wasn’t able to actually think like a man, it just had brutal force that was calculating every possible move in the game. That’s not quite intelligent behavior, but it did the job. In 1996, Deep Blue was able to calculate 50-100 million moves per second! With such power, It stepped on the battle field against Garry Kasparov and – lost.
Yes, such a powerful machine couldn’t beat such great chess player as Garry Kasparov. IBM then stepped up, improved the computer, simply by doubling the number of chips and improving a little bit software, so then it could calculate over 300 million of chess moves per second! The rematch was appointed and in 1997 it finally succeeded to won against Kasparov. Interesting thing is that, even then, it was tight – computer won in the deciding game when Kasparov made a mistake during the opening. Kasparov said that he felt something like “human intelligence” in some moves and demanded to see printouts of the machine’s log files but IBM refused. Later they published those files on the Internet. Kasparov also demanded a rematch, but IBM also refused. The results – Deep Blue will be remembered in the history and IBM’s stocks nicely jumped on the market at that moment.
Last year, one interesting thing happened – Google’s AI called AlphaGo won against world’s best Go player. What is Go and why is this significant?
Go is an ancient Chinese board game and it’s interesting because unlike the chess which is playing on the 8x8 table, Go has 19x19 table! Do you remember my story from the last time about trees, nodes and branches? Go, with such big table and its rules, has enormous branching factor – it has more possible states than there is atoms in the universe! That’s what I call a real challenge. Can we make such powerful computer that can calculate every possible move in this game? Ummmm... no. So how Google succeeded? Are they aliens? Illuminati?
Maybe they are, I don’t know (probably yes), but I know on which principle their AI works. They used one thing about which I was writing two weeks ago – neural networks.
AlphaGo has 48 layers of neurons that search patterns on the table during the game and try to conclude what could be the best move.
Now when Go is conquered, we can say that AI can certainly beat man in every board game.
Oh this is so exciting, I’ll make my own AI that can play games! Yeah... I will... I will go in Vegas and become like Robert De Niro in Casino! Or... or like Joe Pesci hahah he’s so funny man...
Or I can be like Godfather! Yeahhh, that’s the real talk... how can I do that, Nikola please tell me, pleaaaase?
I’m gonna make you an algorithm you can’t refuse.
What exactly AI does while it’s playing a game?
First, we have to define a game as a searching process which is actually competitive. We have two agents who want to lower chances of each other for win. If one agent wins, then other agent must lose.
Now, on your way to become Robert De Niro, you have to get familiar with one term which is called - heuristic.
Heuristic is one very important thing and it is actually a function which works as an additional information that you use in your search strategy to have better results. For example, cost function from the last time when you had to travel from Belgrade to Kruševac could work as a heuristic or if you are trying to solve Rubik’s cube, heuristic can be the number of squares that aren’t on the right place for each color and so on.
It helps you as a parameter which you follow during the search to know how successful you are and what decision you should do next. It’s really, really crucial to choose the best and the most representative heuristic for your problem. How can you know what is the best? Well, that’s the catch – no one will tell you that, it’s something that you have to conclude on your own.
There are few ways to generate good heuristic – first, you can simplify your problem or to break it on more sub-problems and try your assumption experimentally. If it works – good, you can try your heuristic now on the real problem. Second way is learning from experience – you can solve many, many problems that are similar to yours and then you will intuitively know what to choose for your heuristic. At the end, it’s possible to combine more heuristics into one in order to get better results.
Using that logic about heuristics, we can use something called value function. For example, in chess, we can say that pawn has value 1, knight and bishop 3, rook 5 and so on. Also we can make value of the positions of the figures and then we can simply make sum of all of those values and then we have the information how valuable is one state in the chess. Based on that, an algorithm could choose between possible states in order to know what to play next!
But Nikola, how does that algorithm work?
Minimax algorithm
Imagine that we have two agents which are playing against each other and one of them is called MIN and other one is MAX.
Lol, hello my name is MIN hahah it’s so stupid name...
No it’s not. Take a look at this tree on the picture below:
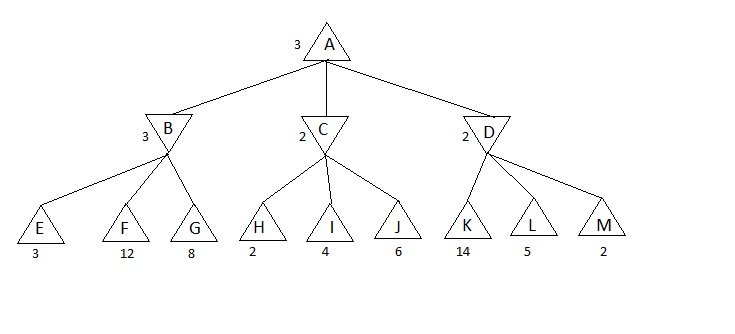
Self-made picture
MAX is called MAX because it tries to find the state with the highest value and analog to that MIN tries to find the state with the lowest value. Take a look at these nodes – let’s say that the nodes which are represented with triangle turned up are the states where MAX chooses its next move and the nodes which are turned down are states where MIN chooses its next move.
According to that, MAX will choose to go from A to B (because 3>2) and then MIN will choose to go to E, because it’s the best possible answer at that moment.
And that’s how this algorithm works.
How did it calculate the values of the nodes?
If you look more carefully, you can see that algorithm first developed whole tree and went to the deepest nodes and there calculated the value of those states. Then, depending on which agent should go there (MIN or MAX) it picked appropriate values and copied it in the parent node. You can see that it’s supposed for MIN to go to E, F or G, so it chose minimal value which is 3 and assigned that to node B. Same logic is used for C, D and for A.
Interesting thing is that this algorithm needs to develop whole tree in order to go to the deepest nodes and calculate values, so the time needs for this algorithm are exponential O(b^m) and you are maybe remembering what I said in my previous part about exponential needs – it’s s c a r y.
So, can we improve somehow this algorithm?
The answer is yes – we can use its improved version called Alpha-beta pruning.
Alpha – Beta pruning
The trick is that we can conclude in which nodes MIN or MAX can’t go and simply to prune that part of the tree. We are pruning the parts which just can’t affect our future decision. Look at the example below:
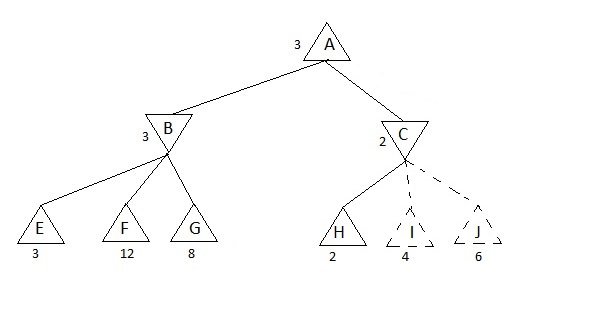
Self-made picture
Let’s say that MAX is in the A and it choses where to go, to B or C. First it developed B and as we can see, by the logic which I described above, it will assign value 3 to the node B. Now, when it starts exploring C, it first sees that H has value 2, so pay your attention right now – two is the biggest value that can be assigned to C (remember, we are taking minimal value from deepest nodes here) so we don’t need to explore further successors of the C node because we saw already that B has already value 3, so MAX will never go to C and we can prune now its successors and save our memory and time.
I hope that I was clear.
And that’s how the Alpha-Beta pruning works.
I gave you a small insight in how those algorithms work in the world of board games and, of course, there are much more strategies and modifications. Right now, AI succeeded to accomplish pretty much everything in this area, so it’s interesting to see what could happen next, in the future. What a time to be alive, literally.
Gambling is the next industry that could be heavily affected by the AI development and right now there are bots that could probably beat you in poker and take your money, house, car...wife.
Just joking, she will probably go by herself.
For the end I will just quote Omar Little, from the best tv show ever made:
It’s all in the game, yo! All in the game...
I hope that you enjoyed,
Many thanks to my tireless mentor @scienceangel who's always here to help me with my ideas.
Sources:
Artificial Intelligence: A Modern Approach, Peter Norvig and Stuart Russell
Artificial Intelligence: The Very Idea, John Haugeland
Sci-Show
Kasparov vs. Deep Blue
This post has been upvoted by the user-run curation platform CI! In this platform users are able to manually curate content. This is done regardless of Steem Power, for both rewards and vote size calculation.
Join in at our site here!
Or join us on discord to interact with the community!
This post was given a rating of: 0.9932218507679217
This post was voted: 100%
I think you must tell us 1) how you programmed those images to be self-made and 2) are they conscious? :D
Lmaooo
Maybe I'll write about that in my next post, stay tuned :P
Hello @nikolanikola :)
I was looking forward to what you were going to bring us next in your series :) I was interested in this one because my husband loves playing chess against the computer. I particularly liked the section What exactly AI does while it’s playing a game?, especially when you discuss heuristics. It is all so relatable to my field :)
Well, you did say at the beginning that we could look at our situations in life as if they are a game. After all, we should all be working on decisions that yield the best outcome for us.
All the best to you my dear :*
Hi dear Abi :)
It's flattering to know that someone is somewhere waiting for my next post in this series :)
Yes, heuristics could be found in other sciences, not just in computer related. As a matter of facts, psychology is pretty important when it comes to creating of some higher level of AI, because at the end we're trying to "bring life" to something and to live with it in this world :)
Of course we should bring our best, but sometimes the best outcome for us means the worse outcome for someone other. Then we should make a small compromise.
Thank you for stopping by, hope you are well :)
Here's one Wednesday kiss for you 😜 😘
Oh! 😍 Wednesday kisses are awesome! And, because I’m not greedy like someone I know ( just saying 😌), I am very happy with one! 😃😛
I was considering to give you another one, because I'm not thrifty like someone I know, but I've just changed my mind now 😜
AHahahahaha ahahahahaha
This is great! On chess and artificial intelligence, the Kasparov vs Deep Blue match was epic, but projects like AlphaZero and Leela are even more impressive. The Monte Carlo algorithm seems to be better than MinMax in this field.
Hi @eniolw, thanks :))
The Monte Carlo can be extremely useful in cases when we don't have fully observable environment like when we play cards or when we have some stochastic process like throwing dice :)
Minimax was just an example how this logic works, I personally don't know is it still used somewhere today:)
It is! conventional chess engines use extensively MinMax as search algorithm, but in December of last year, Google proved with AlphaZero that Monte Carlo and reinforcement learning can achieve better results. That is why Leela Chess was born and currently she has caught top chess engines in playing strength.
Just gonna resteem this so that I can have it on my feed as reference for another time! Insightful article!
Thank you @digitalpnut :)
Nicely put together post and a good top-level summary on alpha-beta pruning.
Got a good chuckle from the
I might use that in the future -with attributions of course ;-)
Posted using Partiko Android
hmm maybe I should put some copyright license to that?🤔🤔
Thanks @jasonbu!:))
LOL - had to open my mouth :-)
Congratulations! Your post has been selected as a daily Steemit truffle! It is listed on rank 11 of all contributions awarded today. You can find the TOP DAILY TRUFFLE PICKS HERE.
I upvoted your contribution because to my mind your post is at least 11 SBD worth and should receive 255 votes. It's now up to the lovely Steemit community to make this come true.
I am
TrufflePig, an Artificial Intelligence Bot that helps minnows and content curators using Machine Learning. If you are curious how I select content, you can find an explanation here!Have a nice day and sincerely yours,

TrufflePigTech Bloggers' Guild! The Tech Bloggers' Guild is a new group of Steem bloggers and content creators looking to improve the overall quality of our niche.I will be featuring it in my weekly #technology and #science curation post for the @minnowsupport project and the
Wish not to be featured in the curation post this Friday? Please let me know. In the meantime, keep up the hard work, and I hope to see you at the Tech Bloggers' Guild!
If you have a free witness vote and like what I am doing for the Steem blockchain it would be an honor to have your vote for my witness server. Either click this SteemConnect link or head over to steemit.com/~witnesses and enter my username it the box at the bottom.
thank you :)
Great post! What amazes me most is that a human defeated a computer that could calculate 100 million moves per second. That's impressive!
Thanks @anevolvedmonkey :)
Yes, but it wasn't some regular human, it was The Human :D
This post has been voted on by the steemstem curation team and voting trail.
There is more to SteemSTEM than just writing posts, check here for some more tips on being a community member. You can also join our discord here to get to know the rest of the community!
<3
Congratulations @nikolanikola! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
Click on the badge to view your Board of Honor.
If you no longer want to receive notifications, reply to this comment with the word
STOP