Hi,
In this neural network, we are trying to recognize cats vs. non-cats. For that, we are given a training dataset of 209 images and a test dataset of 50 images. The size of one image is 64*64 pixels, and since those images are colored images there are three channels. We are feeding images one by one to the neural network. There are several ways of feeding an image to a neural network. In this example, a flattened image is fed to the neural network and as a result of that, the number of neurons in the input layer equals 12288 (64pixels * 64pixels * 3channels).
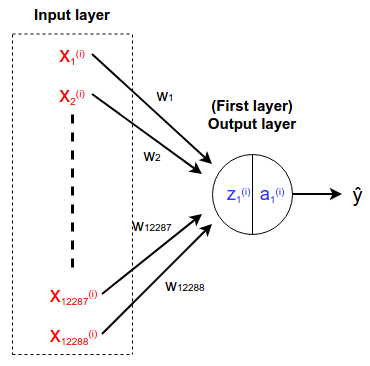
In this network, we don't have any hidden layer and the output layer is the first and only layer. In the output layer, we expect a value between 0 and 1. If that value is greater than 0.5, it is considered as a cat. Therefore we have only one neuron in the output layer. Please refer to the attached image to get an idea about the network architecture.
When we consider the implementation of the neural network, we need to write equations for the forward propagation, cost, backward propagation and updating weights and bias. Forward propagation equations are mentioned below.
eqn (1) : z1(i) = w1x1(i) + w2x2(i) + ... + w12288x12288(i) + b
eqn (2) : ŷ(i) = a1(i) = g(z1(i))
Now we should calculate the cost per data(L) and cost for the whole dataset(J).
eqn (3) : L(a1(i), y(i))(i) = -y(i)log(a1(i)) - (1 - y(i))log(1 - a1(i))
eqn (4) : J = (Σi=1mL(a1(i), y(i))(i))/m
Now we should calculate the derivative for each weight and bias(∂J/∂w1, ∂J/∂w2, ∂J/∂b2, ... ) such that the cost should be reduced in each iteration. Let's try to calculate the ∂J/∂w1 and I will write ∂J/∂w1 as ∂w1. By the chain rule we can calculate the ∂w1 as follows.
eqn (5.1) : ∂w1 = ∂J/∂w1 = (Σi=1m∂L(i)/∂w1)/m
eqn (5.2) : ∂L(i)/∂w1 = ∂L(i)/∂a1(i)*∂a1(i)/∂w1
eqn (5.3) : ∂a1(i)/∂w1 = ∂a(i)/∂z1(i)*∂z1(i)/∂w1
Using eqn (5.2) and eqn (5.3),
eqn (5.4) : ∂L(i)/∂w1 = ∂L(i)/∂a1(i)*∂a(i)/∂z1(i)*∂z1(i)/∂w1
By getting the derivative of the eqn (3) w.r.t. ∂a1(i),
eqn (5.5) : ∂L(i)/∂a1(i) = - y(i)/a1(i) + (1-y(i))/(1-a1(i))
Let's assume activation function g() is sigmoid function. Therefore ∂a(i)/∂z1(i) equals the derivative of sigmoid function.
eqn (5.6) : ∂a(i)/∂z1(i) = a1(i)(1 - a1(i))
By getting the derivative of the eqn (1) w.r.t. dw1,
eqn (5.7) : ∂z1(i)/∂w1 = x1(i)
By substituting eqn (5.5), eqn (5.6) and eqn (5.7) into eqn (5.4) and simplifying the expression,
eqn (5.8) : ∂L(i)/∂w1 = (a1(i) - y(i))x1(i)
By substituting eqn (5.8) into eqn (5.1),
eqn (6) : ∂w1 = (Σi=1m(a1(i) - y(i))x1(i))/m
Following the eqn (6), we can write derivate for all weights.
∂w2 = (Σi=1m(a1(i) - y(i))x2(i))/m ...
∂w12288 = (Σi=1m(a1(i) - y(i))x12288(i))/m
Since ∂z1(i)/∂b = 1,
eqn (7) : ∂b = ∂J/∂b = (Σi=1m(a1(i) - y(i)))/m
Now we have to update the weights and bias as shown below.
eqn (8) : w1 = w1 - α*∂w1 ...
w12288 = w12288 - α*∂w12288
eqn (9) : b = b - α*∂b
Finally, we have derived all the questions we need to implement our neural network. In the next blog post, I will explain to you how to implement our neural network using theses equations. Please feel free to raise any concerns/suggestions on this blog post. Let's meet in the next post.
Congratulations @boostyslf! You have completed the following achievement on the Steem blockchain and have been rewarded with new badge(s) :
You can view your badges on your Steem Board and compare to others on the Steem Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPTo support your work, I also upvoted your post!
Vote for @Steemitboard as a witness to get one more award and increased upvotes!