Search algorithms (search engine algorithm) - a special mathematical formula with the help of which search engine decides which websites to give you in a search result. It is well known that search engines find sites through specific keywords and phrases. Search algorithms are used to find websites that match the search request of the user.

And today I would like to tell you something more about this and our example is Goggle's algorithms.
The logic of the work of search engines is often the same: to collect information from all web pages on the network and process this data so it would be convenient for a search.
And now let's talk more about it.
Algorithms of direct and inverted indexes
It is obvious that the method of a simple search through all pages stored in the database will not be optimal. This method is called direct search algorithm, and despite the fact that this method can surely find the right information without missing anything important, it is not suitable for handling large amounts of data, because the search will take too much time.

Therefore, to work effectively with large volumes of data an algorithm of inverted indexes was developed. And, it is used by major of search engines in the world. Therefore, we discuss it in more detail and look at how it works.
When using an algorithm of inverted indexes there is made a transformation of documents into text files containing a list of the available words.
The words in these lists (index files) are arranged in alphabetical order and next to each of them there are coordinates of those places where these words were on a web page.
Search engines are looking for information not on the Internet, but in the inverted indexes. Although direct indexes (original text) are also stored.
The algorithm of inverted indexes is used by all systems, because it allows to speed up the process, but there will be a loss of information due to distortions introduced with the conversion of the document into the index file.
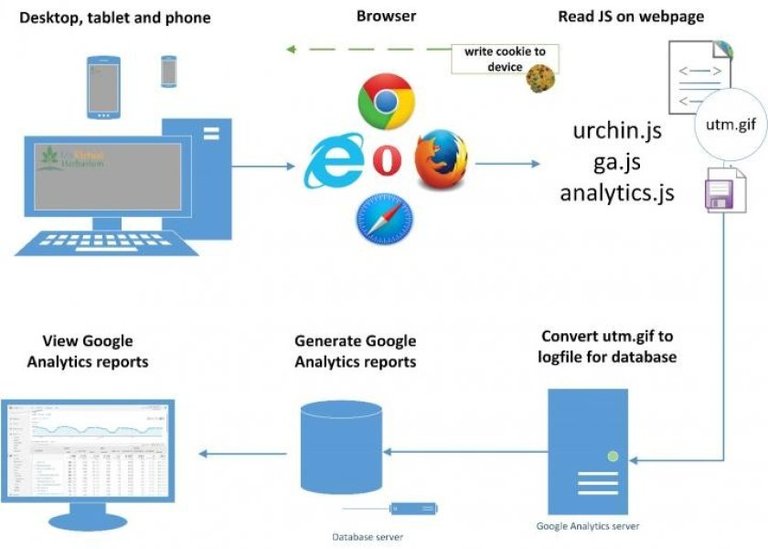
The mathematical model used for ranking
A mathematical model that simplifies the process of finding relevant web pages and a process of determining the relevance of such documents to the request is used for an inverted search. The more it corresponds to this request, the higher it should be in the search results.
So the main task of the mathematical model – is to search for pages with inverted indexes that correspond to this request and its sorting in relevance descending order.
The search engine should not only provide a list of Web pages on which there are words from your request. It should make the sorting by relevance.
The mathematical model used by all search engines belongs to a vector class. It uses a concept such as the weight of the document in relation to a specific user request.
In the basic vector model weight of a document is calculated based on two main parameters: the term frequency and inverse document frequency.
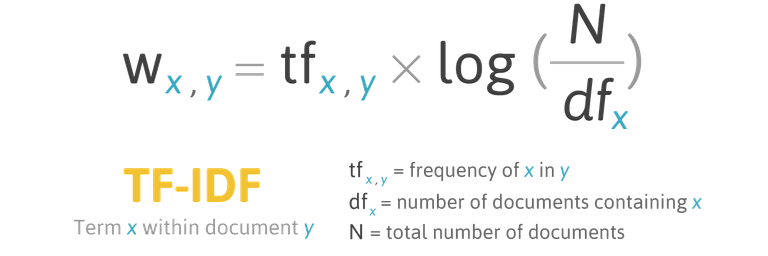
Various search engines, use not only TF and IDF parameters, they use many different factors to calculate the weight, but it remains the same: the page weight will be greater if the word from the search request is found in it more frequently and less frequently in all other documents indexed by the system.
Thus it turns out that the formation of search results is carried out entirely by the formula without human intervention. But no formula will work perfectly, especially at the beginning, so you need to monitor the work of the mathematical model.
There are specially trained people - the assessors who are browsing the search results for various requests and evaluate the performance of the current formula.
All the comments made by them are accounted by people who are responsible for setting a mathematical model. Different changes or additions are made to increase the quality of work of a search engine.
Through years Google have got a lot of different algorithms and they all were using different mathematical models, worked with a different speed and so on.

If you would like this topic, I'll write about all of them and their characteristics as it is really interesting!
Follow Me to learn more about popular science and scientific topics.
With Love,
Kate
It was said that Google is over ranking content on Steemit . It is really so?
https://steemit.com/steemit-ideas/@ash/idea-protect-content-owners
Thanks for the link. I didn't know that.
IMO plagiarised content harms this platform. I saw that there is a bot that checks all the posts on plagiarism and of there is any, it notifies readers in comments
Relevant links are also important.
So the content analysis is not only on current document, but also on referers.
This article was focused more on how it finds results relevant to your search terms, not about how it ranks them. With the old PageRank algorithm, Google ranked results based exclusively on how many other important pages linked to them. I'm not sure how important that is with their current ranking method, however.
May be it would be interest to say a few words about web spiders...
It is really a big problem to find new pages -- for example, the mean function of browser addons from most search engines is to collect user urls.
Actually, I only wrote about their new algorithm 'RankBrain' in my post here a few days ago. The news is, it is very good for #steemit.
wow. Well done. A very good article devoted to RankBrain that I didn't notice 3 days ago. Now subscribed to your updates
Thank you for this information. I have been working as seo for 6 years. Nobody knows actual algorithms of Google.
I laugh a lot with the writing cookie on one of your image :)
Thanks, as usual ^^
You post some cool IT stuff in your blog :-)