Motivation
This is a sort of follow-up to my previous post analysing voting behavior on the steem blockchain. What I'll demonstrate here is a few methods to seperate posts with questionable voting patterns from posts that appear more organic, as well as digging into the voters on the less organic posts to see if we can find some patterns that help to tell us the extent of bot use in top posts. In this post we'll take a look at the number of posts arriving per second for given posts and the crossover in these voting spikes.
Background and Tools
For background please refer to my previous post, particularly the Background, Imports, Data and Helper Function sections. These explain how I got the data and the basic functions that I use to process it. Note: for this analysis I'll use the same data (January 2018).
Process
For clarity I decided not to do any python magic for finding maximum values (this will become more clear right away) so I wrote this simple looping function to find the max element of the first list in a 2xN list and return both values.
def max_both(lst):
mx = lst[0][0]
other_max = lst[1][0]
for i,element in enumerate(lst[0]):
if element >= mx:
mx = element
other_max = lst[1][i]
return mx, other_max
The below code using the relative_times function (which takes all votes on a post and returns their time relative to the post creation) from my previous post. A histogram is then generated using these values with a bin size of 1 second. This tells us how many times a post was voted for in each 1 second period after it was created. All we really care about here is the maximum number of votes that happened in a 1 second. The idea is that if we see a post where the maximum number of votes per second is un-reasonably high, we know that an army of bots hit the post, or a curator with a reasonably large trail voted for it. We'll also keep a list of when these peaks happened so we can perform some analysis later.
# Votes per second
vps = []
# The lower end of the time bin
time_slot = []
for post in top_posts:
relatives = relative_times(post, scale = 1)
hist = np.histogram(relatives, bins = int(max(relatives)))
vmax, bmax = max_both(hist)
vps.append(vmax)
time_slot.append(bmax)
print("The maximum number of posts per second is: {0}".format(max(vps)))
plt.plot(vps)
plt.ylabel("Votes per Second")
plt.xlabel("Post #")
The maximum number of posts per second is: 66
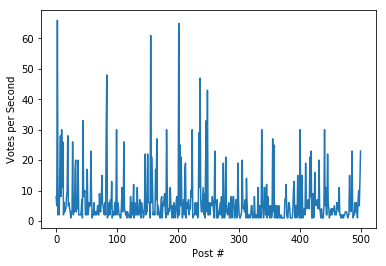
More than 60 upvotes in 1 second? Unlikely without bots or curation trails. While anything above 1 vote per second feels a bit suspicious to me, we'll take 10 to be the cutoff and assume that > 10 upvates per second implies the use of bots.
bot_posts = [top_posts[i] for i in range(len(vps)) if vps[i] > 10] # 77 posts
Below we have some fairly simple code to compare the total number of votes in a time period (January 2018) to the number of unique voters in the same period. We do this using a set, which in python is guarenteed to not have duplicate entries. We add voters name to this set and after all the voters the length of the set will be the number of unique voters. Note: this isn't the most "pythonic" way to do this, but it's more clear with 2 for loops.
votes = 0
unique_voters = set()
for post in top_posts:
for vote in post['active_votes']:
unique_voters.add(vote['voter'])
votes += 1
print("Votes: {0}".format(votes))
print("Unique Voters: {0}".format(len(unique_voters)))
print("Unique %: {0}".format(100 * len(unique_voters) / votes))
| Votes | 230,936 |
| Unique Voters | 49,271 |
| Uniqueness | 21.3% |
So for all the top 500 hundred posts in January, we have ~230,000 votes given out by ~50,000 voters. So we saw this is ~21% unique. We'll use this as our baseline for comparison.
Next we do the same thing, but only for posts that we've classified as "using bots" (i.e replace top_posts with bot_posts in the above code).
| Votes | 63,102 |
| Unique Voters | 26,217 |
| Uniqueness | 41.5% |
So over these posts we see ~63,000 votes with ~26,000 unique voters, this gives a uniqunes of ~42%! This means that posts that have a big dump of votes at once tend to have less overlap in voters!
For interest sake, lets change the cuttoff for suspicious posts to 20 and 30 votes per second. We do this by creating 2 (poorly named) new variables. Again we'll replace top_posts in the above code with bot_posts2 and bot_posts3.
bot_posts2 = [top_posts[i] for i in range(len(vps)) if vps[i] > 20] # only 38 posts
bot_posts3 = [top_posts[i] for i in range(len(vps)) if vps[i] > 30] # only 8 posts!
20 vote cutoff
| Votes | 37,021 |
| Unique Voters | 19,942 |
| Uniqueness | 53.9% |
30 vote cutoff
| Votes | 11,248 |
| Unique Voters | 8,374 |
| Uniqueness | 74.4% |
Weird! Our uniqueness continues to increase from ~21% to ~42% to ~54% and finally to ~75%. If some of these top posters are using bot armies, it's starting to look a lot like they've all using independent ones, it also seems likely that those massive spikes are coming from huge curation trails.
Let's try looking at the bots that are actually involved in those spikes, maybe there will be some crossover? The following code runs through every post and creates a lists containing all the votes that happened in a specific time bin (the bin with the maximum number of votes). The logic here is that maybe these posts are gaining a large number of unique votes by first bumping their visibility usings bot votes or other methods. If the python here is a little confusing just ignore it and know that we've extracted the voters involved in the spikes outlined above.
# Need to cull the time_slots the same way we did the histogram peaks
times = [time_slot[i] for i in range(len(vps)) if vps[i] > 10]
spike_votes = []
for post, bn in zip(bot_posts, times):
spike_votes.append([])
relatives = relative_times(post, scale = 1)
for r, voter in zip(sorted(relatives), post['active_votes']):
if bn <= r <= bn + 1: # == index:
spike_votes[-1].append(voter)
Now we can use the same code as above to generate uniqueness for the posts above the first threshold of 10 votes per second. This give us 1,738 votes with 1,401 unique voters giving a uniquness of ~80%. Now we're gonna use spike_votes instead of top_votes in the code a bit higher up and we get our new numbers.
| Votes | 1,738 |
| Unique Voters | 1,401 |
| Uniqueness | 80.6% |
Conclusion
I'm not sure what we can conclude about this. I started this analysis expecting to see a large amount of crossover between the top posts (or at least the ones with massive spikes) but instead it appears that these are the most unique of any portion of the votes. In hindsight this actually makes sense, if these posts are using bots to boost their vote counts (not total rewards) then they would need an army of smaller bots, which can probably only vote ~10 times per day. Of course a less pessimistic (and probably more accurate) interpretation of these results would suggest that these spikes are probably the result of curation trails. If you have any other interpretations of this data, or just any thoughts, please leave a comment below.
Addendum
And just as a sort of sanity check I did the uniqueness check for all posts that had < 10 votes per second maximum. As you can see this is fairly in line with what you might expect, it's not quite as low as the ~21% uniquness of including all posts, but it's fairly close to it. This will look fairly similar to the way we generate bot_posts but will instead only take posts with < 10 votes per second max.
not_bot_posts = [top_posts[i] for i in range(len(vps)) if vps[i] < 10]
| Votes | 163,473 |
| Unique Voters | 40,310 |
| Uniqueness | 24.7% |
Posted on Utopian.io - Rewarding Open Source Contributors
Thank you for the contribution. It has been approved.
From the data, I can tell that there are votes per second. Is this for a single post only? Or 600+ votes per second but on different posts. Without looking into the details, what I can infer is that users just want to get a big number of votes to go into the trending perhaps? But these number of votes were made by by a unique number of users? So I guess I also don't know what to conclude from it.
But I'd like to propose/suggest is, my impression here is that you're somehow looking for the bad guy/s. What I'd like to suggest is to analyze optimistically - look for the good guys and highlight them.
You can contact us on Discord.
[utopian-moderator]
This is actually for a selection of 500 posts from January, but the numbers quoted (maximum of 66 votes per second) are for individual posts. It is true though, I think it would be very unfair to attempt to draw any firm conclusions from the data above.
That's an interesting angle! Highlighting strong curators could certainly be beneficial!
Hey @eastmael, I just gave you a tip for your hard work on moderation. Upvote this comment to support the utopian moderators and increase your future rewards!
.
That's a very good point! I didn't realize that the timestamp was block time, not creation time. To confirm that, I checked against the posts I have saved and regenerated the graph I have shown above using 3 second bins. I would attach it here, but it is predictably identical to the one above! I still maintain that ~60 votes in three seconds (~20 votes in one) is moderately suspicious (although certainly less so).
That's a good suggestion! I think for my next post, I may look into clustering voters to see this kind of grouping. I'd also like to look into voters based on SBD value they've added to the post.
Thanks for reading!
Hey @calebjohn I am @utopian-io. I have just upvoted you!
Achievements
Community-Driven Witness!
I am the first and only Steem Community-Driven Witness. Participate on Discord. Lets GROW TOGETHER!
Up-vote this comment to grow my power and help Open Source contributions like this one. Want to chat? Join me on Discord https://discord.gg/Pc8HG9x