I divided the entire dataset in the ratio 80:20 into a training and test set. After training the model, I carried out the test, resulting in the following confusion matrix.
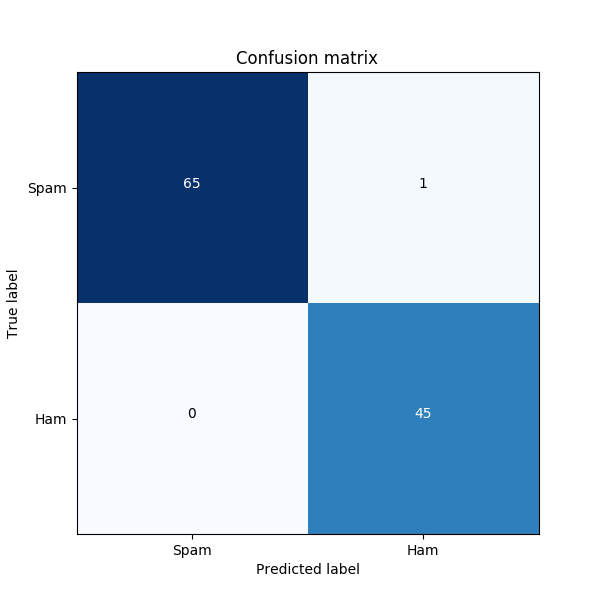
As you can see, the results are pretty good here. Only one type II error (False Negative).
But the real challenge here is precisely defining what is spam and what is not. At the beginning I was probably too overzealous, now I try to balance it more. Therefore, for example, I do not treat single comments like nice photo or please follow me as true spam, but only when they are repeated over and over again.
That is why I constantly analyze the results and, if necessary, I make corrections in the data set / parameters, so that it all works well in practice, and not only in theory. The other thing is the fact that a lot of comments that the bot classifies as spam have to be ignored (bid-bots, photocontests, welcoming users) because marking them as spam would not end well :)