
logo by @camiloferrua
Repository
https://github.com/to-the-sun/amanuensis
The Amanuensis is an automated songwriting and recording system aimed at ridding the process of anything left-brained, so one need never leave a creative, spontaneous and improvisational state of mind, from the inception of the song until its final master. The program will construct a cohesive song structure, using the best of what you give it, looping around you and growing in real-time as you play. All you have to do is jam and fully written songs will flow out behind you wherever you go.
If you're interested in trying it out, please get a hold of me! Playtesters wanted!
New Features
- What feature(s) did you add?
Recently The Amanuensis got an intelligence upgrade with a complete rework of the section of code handling its rhythmic analysis, colloquially called its "consciousness". I describe here another upgrade featuring an in-depth presentation-view visualization of the analysis as it's being conducted, which essentially shows the player a scoring of what they're playing. In addition, it will be important in understanding how well the analysis itself is working and giving clues as to how it might be improved in the future.
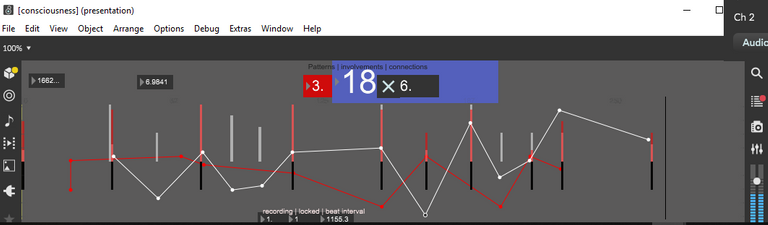
the updated consciousness.maxpat presentation view, which displays an ensemble of stats regarding your playing and the recorded material
At the top of the above screenshot you can see the 3 essential "scores" determined for each of the players' notes: patterns, involvements and connections.
Taking into account every note in a local vicinity, including those just played and those already recorded, a pattern is found when an interval between the played note and another is repeated consecutively at least once. Multiple patternscan be found from a single note by projecting both backwards and forwards in time looking at different note intervals.
The number of involvements is the quantity of notes demarcating the intervals of all patterns the played note is a part of. This will always be at least 3 for each pattern, since it takes 3 notes to create 2 consecutive intervals, 4 to create 3 consecutive intervals, and so on.
Connections are involvements with notes that have already been recorded, rather than the user's real-time playing. These are the most important scoring metric and recording will begin when the played note has at least 1 of them, as they ensure that everything that winds up in the song is part of a sort of rhythmic "lattice".
This lattice is essentially the quarter-note, half-note, whole-note, etc. structure traditionally given to define the timing of music, but far more free-form, allowing you to use any sort of crazy time signature you can manage to play. As long as there are repetitions occurring in the timing intervals of the notes, it will be acknowledged. The black hashmarks seen in the new GUI represent this lattice, the positions of the already-recorded beats.
The white hashmarks represent the user's real-time playing and vary in height according to the number of patterns the note is involved in. This is essentially the involvements score for that note, except that it can be added to retroactively as new notes come in. Watching how the white hashmarks grow over time can give you an idea where lie the rhythmic intervals it was found to be a part of.
The colored hashmarks are the same as the white, except they represent and take into account only the song "recitation", or the already-recorded notes. This means that every involvement visualized with these is also a connection. Each track has a unique color and their statistics appear simultaneously. Where these hashmarks overlap the colors will blend (for example where you see pink in the above screenshot) and these will represent important moments of synergy rhythmically.
The overlaid line graph is another way to visualize what's happening in real time. Again, the white line represents the users playing and colored lines represent recorded notes by track. Currently it is strictly graphing involvements, but it could be easily changed to graph patterns, connections or any other metric the analysis can spit out. In theory, places where the white line rises above the colored line could be improved and made more rhythmically stable by recording that new material into the song, but this will have to be analyzed with further development.
- How did you implement it/them?
If you're not familiar, Max is a visual language and textual representations like those shown for each commit on Github aren't particularly comprehensible to humans. You won't find any of the commenting there either. Therefore, the work completed will be presented using images instead. Read the comments in those to get an idea of how the code works. I'll keep my description here about the process of writing that code.
These are the primary commits involved:
The first thing I wanted to have visualized was the users' playing, to make sure patterned intervals were being found and where exactly they were. These are the white hashmarks and were implemented using a waveform~ to display the contents of a new buffer~ lattice. This may not be the most intuitive UI object to utilize for this purpose, but the only real way to convey a long list of data from gen to the outside code is through buffer~s. In the end, it does wind up being a pretty lightweight option as well.
The gen code I'm referring to is rhythm.gendsp, which was heavily modified to assess these new data variables by adding code such as the following whenever a pattern is found:
local_pattern = 1;
connected = 1;
quantized = (check - song_start) / atom;
lattice.poke(lattice.peek(quantized) + .1, quantized);
involvements += 1;
connections += 1;
and
if(local_pattern) {
quantized = (now - song_start) / atom;
lattice.poke(lattice.peek(quantized) + .1, quantized);
quantized = (past_timestamp - song_start) / atom;
lattice.poke(lattice.peek(quantized) + .1, quantized);
patterns += 1;
involvements += 2;
}
Rather than trying to display exact pinpoint millisecond moments in the external waveform~, a "lo-res" quantized scaling is used. This displays in units of atoms (default 18 ms) which are chunkier and easier to see.
Previously, rhythm.gendsp was only programmed to find the first "connection" with the established song and to stop processing at that point. To gather these more in-depth stats it was necessary to remove various breaks and if(!connected) { lines throughout. This certainly can put a heavier load on the CPU with more extensive songs and performance must continue to be monitored as testing progresses.
Next it was desired to visualize and conduct the analysis on the "recitation", or beats in the already-established song, as well. This was conducted in the same place as future beats are added to buffer~ song for analysis, document_song in consciousness.maxpat.
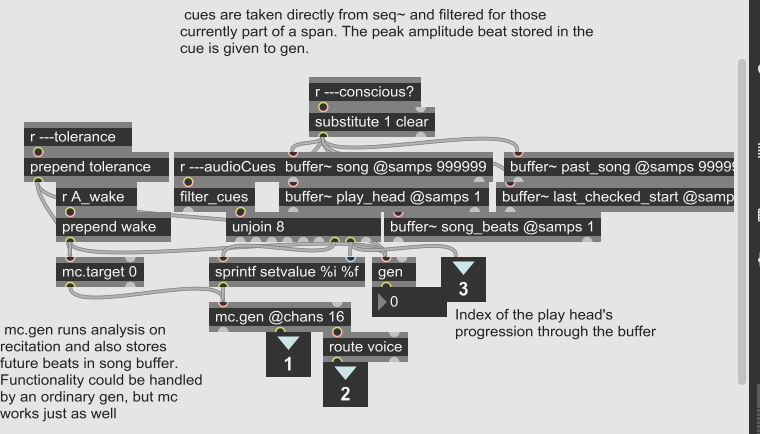
the augmented document_song in consciousness.maxpat, complete with commenting
In an mc.gen, genxper code was added similar to that of rhythm.gendsp, but that was heavily modified to not take into account the users' playing and to only serve the function of filling the lattice visualization buffer~. The buffer was modified to have 17 channels so that each track of recitation could take its corresponding channel (with the users' playing taking channel 0). Separate waveform~s with transparent backgrounds were overlaid on the presentation view to each display one of these channels.
/*
every already-recorded beat is analyzed, comparing every interval between the other song beats
in the local vicinity and it documenting any subsequent intervals. Every instance of subsequent
intervals is tallied as a "pattern". Every beat involved in a "pattern" is tallied as an "involvement".
*/
involvements = 0;
patterns = 0;
prior_song_beat = play_head.peek(0); //play_head is at most recent song beat (in the past)
song_size = song_beats.peek(0);
for(j = prior_song_beat + 1; j < song_size - 1; j += 1) { //reverberate forward through song
future_beat = song.peek(j);
interval = future_beat - timestamp;
if(interval && interval <= tolerance) { //success; played beat coincides with a song beat
quantized = (timestamp - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
quantized = (future_beat - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
involvements += 2;
}
else if(interval <= wake + atom) {
target = future_beat + interval;
patterned = 0;
for(k = j + 1; k < song_size; k += 1) { //check remaining beats
check = song.peek(k);
if(abs(check - target) <= tolerance) { //success
patterned = 1;
quantized = (check - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
involvements += 1;
target += interval;
}
if(check > target + tolerance) { //overshot
break;
}
}
if(patterned) {
quantized = (timestamp - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
quantized = (future_beat - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
patterns += 1;
involvements += 2; //+2 for beat and future_beat
}
}
else {
break;
}
}
j = 0;
past_beat = past_song.peek(j);
while(past_beat) { //reverberate backward through song
interval = timestamp - past_beat;
if(interval && abs(interval) <= tolerance) { //success; played beat coincides with a song beat
//abs() because it's possible it past_beat might actually be in the future
//(Documented at cue start rather than envelope peak)
quantized = (timestamp - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
quantized = (past_beat - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
involvements += 2;
}
else if(interval <= wake + atom) {
target = past_beat - interval;
patterned = 0;
k = j + 1;
check = past_song.peek(k);
while(check) { //check remaining beats
if(abs(check - target) <= tolerance) { //success
patterned = 1;
quantized = (check - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
involvements += 1;
target += interval;
}
if(check < target - tolerance) {
break;
}
k += 1;
check = past_song.peek(k);
}
if(patterned) {
quantized = (timestamp - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
quantized = (past_beat - song_start) / atom;
lattice.poke(lattice.peek(quantized, mc_channel) + .1, quantized, mc_channel);
patterns += 1;
involvements += 2; //+2 for beat and past_beat
}
}
else {
break;
}
j += 1;
past_beat = past_song.peek(j);
}
out1 = patterns;
out2 = involvements;
the meat of the genxper code in the newly-added mc.gen in the above screenshot, complete with commenting
The black hashmarks were added to visualize every beat in the song using a new buffer~ playback, to see if there were ever any beats that were no longer connected to the rest of the song. This was accomplished with the following lines of code.
quantized = (timestamp - song_start) / atom; //visualize all song beats in playback buffer
playback.poke(-0.5, quantized);
One of the essential benefits of these visualizations is that certain necessary improvements become apparent. Two of these were
a) upon import, the beats in the song needed to be added all at once rather than waiting to add them in real time as the song progresses, otherwise they would be missing from the analysis on the first run through.
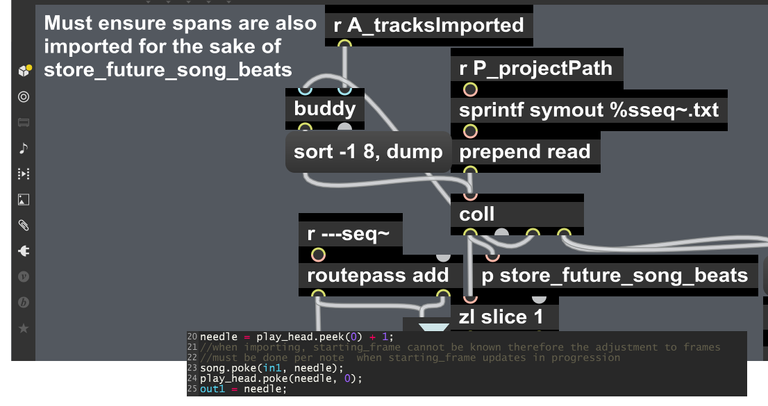
the modifications to store_cues in organism.maxpat and the essential bit of genxper code inside the new store_future_song_beats, complete with commenting
b) the conversion from beats (as given from the seq~) to absolute millisecond timestamps (a.k.a. frames) for song beats needed to occur after the starting_frame was updated at the beginning of each loop of the song, otherwise they would actually be referring to moments in the past or, in the case of import, would be unknowable completely.
starting_frame.poke(now, 0); //with starting_frame updated, all future
for(i = 0; i < dim(song); i += 1) { //song beats (imported) can be converted to frames
if(!song.peek(i)) {
break;
}
song.poke(song.peek(i) * click + now, i); //placing them actually in the future
}
the new lines of code added in 2 places in progression.gendsp, complete with commenting
Another of these improvements was in utilizing a loop offset, ensuring that shorter looping tracks would have their beats documented in song for inclusion in the analysis further out into the progression of the song at large than just their original loop (in accurate representation of what the user is actually hearing).

the modified contents of the mc.gen object responsible for the modulo operation in p mc.seq~, now also documenting the number of times each track has looped, complete with commenting
song_start = starting_frame.peek(0);
w_loop_offset = loops_by_track.peek(mc_channel) * beats_by_track.peek(mc_channel) + in1;
timestamp = w_loop_offset * stats.peek(6) + song_start;
…
song.poke(w_loop_offset, needle);
play_head.poke(needle, 0);
the genxper code in document_song updated to account for the loop offset
Finally, I wanted the more intuitive line graphs implemented in the UI in order to compare in real-time any given stat of the users' playing versus any of the tracks' recitation, as they are essentially competing with one another in their rhythmic quality for inclusion in the song. I believe this may be the best way to decide which metrics are, or could be, ideal for judging this competition.
The stats now being output by rhythm.gendsp as well as the new mc.gen in document_song are displayed in overlaid transparent-background functionobjects on the UI, which are managed by the following code in a new subpatcher.
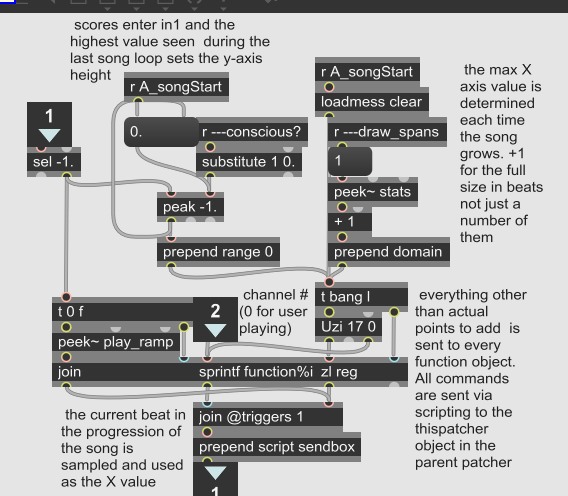
the new function subpatcher in consciousness.maxpat, complete with commenting
GitHub Account
To see a full history of updates, blog posts, demo songs, etc., check out my Steemit blog @to-the-sun.
Until next time, farewell, and may your vessel reach the singularity intact
To the Sun
Your contribution has been evaluated according to Utopian policies and guidelines, as well as a predefined set of questions pertaining to the category.
To view those questions and the relevant answers related to your post, click here.
Need help? Chat with us on Discord.
[utopian-moderator]
Thanks :D
Thank you for your review, @helo! Keep up the good work!
Hi @to-the-sun!
Feel free to join our @steem-ua Discord serverYour post was upvoted by @steem-ua, new Steem dApp, using UserAuthority for algorithmic post curation! Your post is eligible for our upvote, thanks to our collaboration with @utopian-io!
Hey, @to-the-sun!
Thanks for contributing on Utopian.
We’re already looking forward to your next contribution!
Get higher incentives and support Utopian.io!
SteemPlus or Steeditor). Simply set @utopian.pay as a 5% (or higher) payout beneficiary on your contribution post (via
Want to chat? Join us on Discord https://discord.gg/h52nFrV.
Vote for Utopian Witness!