在之前的文章《温故而知新:复习一下字符编码(ASCII、GB2312、Unicode、UTF-8、区位码)》,我复习了一下字符编码相关的问题。但是理论归理论,总要实践一下才会觉得靠谱一些嘛。
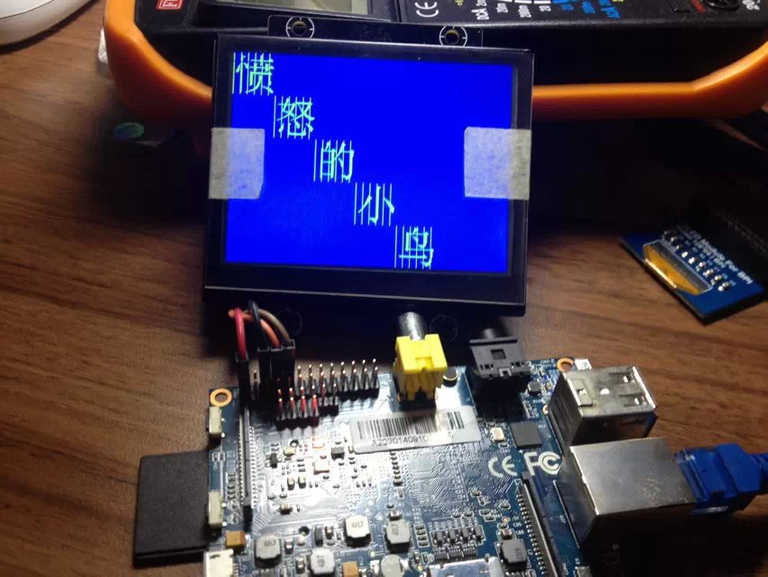
先来秀一下我以前测试汉字库的效果图

其中一个我显示反了😳,真的没有其它含义,我不想造反的。
当初流行愤怒的小鸟,但是我因为计算有误导致字库显示的不正常,不过效果倒是比正常的好看多了呢,我曾戏言是把小鸟关到笼子里。

终于把字显示正常了,哎,好想念婉儿表妹,不知道表妹是否还记得我?
其实从GB2312到区位码再到取字模出来还是比较简单的事情,毕竟就是加加减减乘乘除除的事情。现在很多液晶模块里边都自带字库,给相应的指令去显示即可。不过如果要显示特殊的尺寸规格以及特殊的字体,还是要用到自定义字库的。

扯远了,当初开发单片机程序的时候,因为时常要处理字符编码,所以我写了个超简单的工具给大家查询编码用。这里我用来验证一下之前学习编码那篇文章里涉及的问题。

可见对ASCII字符而言,Unicode(UCS-2)直接在ASCII字节前加上0x00,UTF-8编码出来的字节长度是一个字节和ASCII保持一致。

对于常见汉字(GB2312编码方案范畴内的),Unicode和ASCII方式都占用两个字节,但是两者内容是不同的,并且有不同的叫法,前者叫宽字符(WideChar)后者叫多字节字符(MultiByte)。而UTF-8编码出来占用三个字节,也就是说常见汉字编码成UTF-8反而多占用一个字节。

𐍈一个好特殊的字符,这个字符Unicode(UCS-4)存储占用了四个字节,UTF-8编码出来也是四个字节。因为我系统中设置的Unicode之外的默认编码为GB2312,它支持的范围就是两个字节,所以转换成GB2312多字节字符后会缺失内容。(哦,或者我程序界面上应该用GB2312而不是ASCII更好一些,懒得改了)

𤭢一个好神奇的汉字,据说收录在康熙字典,音义均同“碎”。这个字打破我一直以来都认为汉字Unicode表示只占两个字节的认知。以前听说什么公安局户口录入系统经常遇到敲不出来的汉字,这次我也长见识了。其它方面到和𐍈没啥区别了。
好了,就到这吧,至于什么UTF-16、UTF-32,我就不去学习了,累啊,有了这几把板斧,应该足够我愉快的玩耍了。
GB2132?GB2312?我傻傻的分不清楚,哈哈哈,博主是自我混乱了吗?
感谢指正,我内存溢出,傻掉了😢
哈哈哈😂,手误正常的~
我在想,以你对技术的追求和DIY的兴趣,以后会不会把自己屋子弄的跟科幻片里一样各种高智能化。
甚至还可以结合喜好,弄成神话或者奇幻风格。
真心没那么深厚的实力(无论技术或者金钱)
我觉得代码是未来的通用语言
记得15年还是16年的时候时代周刊出过一期讲了迄今所有的代码语言
O神是否考虑在steemit 上开一门计算机语言课程
教无代码经验的steemians
开一个先河
如有我第一个报名
惭愧,我这水平就自己玩比较合适,教学就贻笑大方了
如果 o神开课我可能能当 TA :D
小鸟、表妹、香蕉……
这画面不要太美 :D
昏倒😵
感觉o哥玩的东西好多,嵌入式、应用软件、营销、古诗词,厉害啊。那么问题来了,这特么哪来的这么多时间...
时间就像是海绵里的水😳
Thats a really nice post regarding Computer Science and internal memoryof the computer.