
In this post, I want to present basic information about The HAF. I think it is a good idea to have described in one place what is The HAF, what are its components, and how they cooperate with each other, with applications, and with the HIVE network.
What does it mean HAF ?
HAF is an acronym from the HIVE Application Framework. In short, it is a software system that allows to easily write applications working on the HIVE blockchain. Such applications read information delivered by blockchain blocks and very often transform them into their specific data.
A high-level view of The HAF
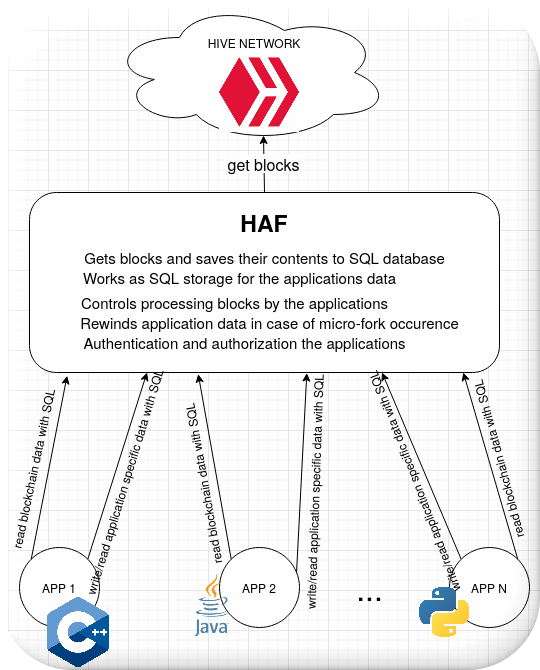
The HAF works between the HIVE network and the applications (App1, App2,...AppN). Below are explained the presented HAF functionalities:
- Gets blocks and saves their contents to SQL database
It gets blocks from the network and presents their data to applications in form of SQL tables. - Works as SQL storage for the application's data
The applications can create their own tables in the HAF SQL database and save their data. - Controls processing blocks by the applications
The HAF drives the applications with processing blocks by telling them which block shall be processed next. The applications will get the arriving blocks in the correct order, the same as the blocks are created in the chain. - Rewinds application data in case of micro-fork occurrence
If the application wants that, the framework can pass to it reversible blocks to process and in case of fork occurrence automatically, transparently for the application, rollback all the changes which were based on abandoned blocks. It allows the applications to present new data immediately after a new block was created, without the need to wait for a moment when the block becomes irreversible. - Authentication and authorization of the applications
The HAF gives some mechanisms that protect the application's data against access by undesirable persons. Each of the applications cannot look at other applications' data, except when they explicitly share their tables.
The HAF API is a set of SQL functions, so the applications can be written with any programming language which has binding to SQL - almost every language has it.
Lets look a little deeper at the framework
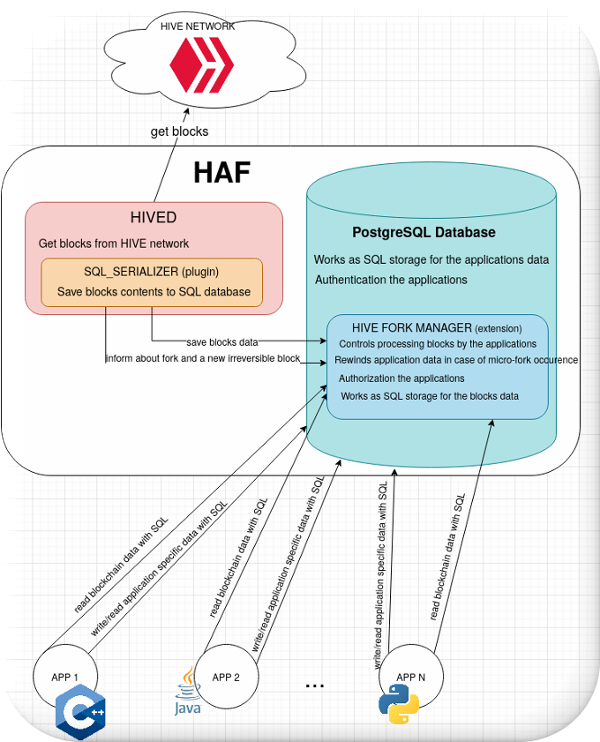
The HAF contains a few components visible at the picture above:
- HIVED - hive node
Regular HIVE node which syncs blocks with the HIVE network or replays them from block.log file.- SQL_SERIALIZER
A hived's plugin (the hive node plugin) which during syncing a new block pushes its data to SQL database. Moreover, the plugin informs the database about the occurrence of micro-fork and changing a block status from reversible to irreversible.
- SQL_SERIALIZER
- PostgreSQL database
The database contains the blockchain blocks data in form of filled SQL tables, and the applications tables. The system utilizes Postgres authentication and authorization mechanisms.- HIVE FORK MANAGER
The PostgreSQL extension provides the HAF's API - a set of SQL functions that are used by the application to get blocks data. The extension controls the process by which applications consume blocks and ensures that applications cannot corrupt each other. The HIVE FORK MANAGER is responsible for rewind the applications tables changes in case of micro-fork occurrence. The extension defines the format of blocks data saved in the database. The SQL_SERIALIZER dumps blocks to the tables defined by HIVE FORK MANAGER.
- HIVE FORK MANAGER
How The HAF can help The HIVE blockchain ?
It allows separating applications codes from code of basic tasks realized by blockchain. The vital tasks of The HIVE, like block producing , blocks evaluation, etc., won't be disturbed by the application's specific requirements. With The HAF we can look at the blockchain ecosystem as a layered architecture:
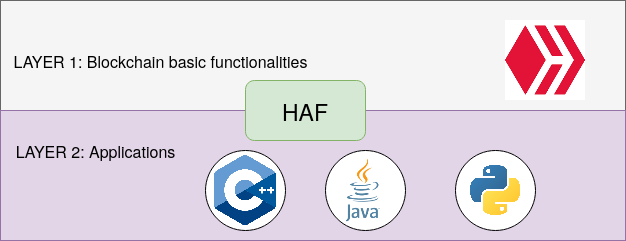
Such architecture gives also benefits to the applications programmers. They get an SQL interface to the blockchain and may start to write simple applications very fast. The complexity of getting blocks and support of micro-forks is hidden behind The HAF. You can see how simple the application can be by looking at the example available on GitLab here
Where are the codes ?
You can find hived code on gitlab here, the SQL_SERIALIZER and HIVE FORK MANGER are parts of HAF project
Will haf ever write data to the blockchain?
Can the apps interact with each other in any way?At the moment we are not working on this. First, we want to support 'read only' applications like account_history or hivemind, but I don't see any reason why the framework cannot be extended in the future to support 'read/write' applications.
What is exactly a 'read/write' application? I thought hivemind could write to the blockchain.
When I follow someone on hive I can see that in block explorers, so isn't hivemind writing to the blockchain?
No, hivemind doesn't write to the blockchain itself. It can only write "2nd layer" information, derived from 1st layer (blockchain) data. When you follow someone on hive, your hive client app actually generates and signs a custom_json transaction (with a follow command embedded inside) that is sent to a hived node to get incorporated into the blockchain itself.
Hived just adds this new transaction to the blockchain, but it doesn't do any analysis/interpretation of the follow (because custom_json operations don't "do" anything as far as the first layer is concerned).
But hivemind sees this operation in the blockchain stream it gets from a hived node and sets the appropriate 2nd layer data so that API calls to hivemind return the appropriate results based on your follow list.
Dstor it!
Thank you, great explanation. So getting back to the original comment on this thread, I still don't get where the question comes from.
If hivemind writes a custom_json to the blockchain, without any interpretation, then as long as you have access to the hivemind code (for example, if it's open-source), you can use that code and read the hive blockchain to re-interpret those custom-jsons and verify everything on your own.
So, every HAF app will be writing custom_jsons on hive, and if the HAF app code is open-sourced, other apps can communicate with that app, given the data is now public.
It just needs some extra work compared to actual writing.
Yes, that's essentially correct.
In fact, I expect most cooperative HAF apps will directly communicate via a shared HAF database . This means that one app can directly read 2nd layer data generated by another HAF app (when the administrator of the HAF servers sets permissions appropriately). This will enable extremely fast and efficient communication, far beyond what is possible today via RPC calls between apps.
So how is every HAF app writing custom_jsons on Hive if there is no read/write ability in HAF
Wow. Thanks for simplifying this into a great knowledgeable piece for everyone to pick it up from it. I love it this way when discussion like this is stretched out. Thanks I followed you @alpha
Maybe I wrongly expressed my thought, currently, HAF does not offer any help with broadcasting transactions (which means it does not help with writing new information into the chain), so when an application wants to react with sending transaction it must deal with this task on its own
how far down the roadmap is the ability for read/write applications?
Right after the moon.
We will be so ready for this bull run in like 100moons
We're not thinking about that at the moment, we need to finish what we're doing now - efficient reading and presentation of blockchain data. I suppose no one will prevent the community from extending HAF to support transaction propagation if it is important to them
~~~ embed:1440906046994796544 twitter metadata:b0FjaWRvfHxodHRwczovL3R3aXR0ZXIuY29tL29BY2lkby9zdGF0dXMvMTQ0MDkwNjA0Njk5NDc5NjU0NHw= ~~~
~~~ embed:1441098402872258573 twitter metadata:dGFza21hc3RlcjQ0NTB8fGh0dHBzOi8vdHdpdHRlci5jb20vdGFza21hc3RlcjQ0NTAvc3RhdHVzLzE0NDEwOTg0MDI4NzIyNTg1NzN8 ~~~
The rewards earned on this comment will go directly to the person sharing the post on Twitter as long as they are registered with @poshtoken. Sign up at https://hiveposh.com.
Even though I don't understand every detail on it I'm still excited about this. Talk about the future for sure.
Is HAF a proposed project or already working project?? But I love the idea
Currently, it is in the testing and bug fixing phase
Ooh, okay sir
It's already being developed
Okay
Will add a reminder to check this out with code later. I'm looking forward to coding apps with this. :)
what I meant to ask with my last question is what's the cheapest VPS I can get if I want to run this somewhat smoothly 24/7 for an app.
Excellent information
Initially I thought this was about yet another Token but no...... it's about the HAF!
Surprise :)
What are the advantages or disadvantages of using HAF instead of HiveSQL when coding in python?
It is hard to compare these two things, I know at first glance they look similar because SQL is an interface for applications in both products, but the main difference is that HAF is a framework to build applications and HiveSQL is a service that responds to SQL queries. HAF is strongly concentrated on applications, it drives them by telling them which block shall they process in the next step, gives them a place to save their own SQL tables, and roll back changes in case of micro-fork occurrence. HiveSQL allows only for asking the remote database. HAF is completely free, all its components, includes the PostgreSQL database, have opened code and the community may participate in its development. HiveSQL has closed code. Because HAF allows saving the applications tables in the same database as the blockchain data are, applications are very performant - they have no delays because of asking for external service. HiveSQl is immediately ready to use ( after subscription ), HAF requires to setup somewhere all of its components, but projects similar to Hive Plug and Play may solve this problem.
In general, to reiterate what I wrote at the beginning, it's hard to compare a framework with a service.
This is a great explantation. Thank you.
Thank you for explaining. I am understanding more and more about HAF. I use HiveSQL sometimes, that's why I was wondering about differences. Your explanation is perfect. Looking forward to experimenting with HAF.
great overview!
I'm glad you like it :)
Quite informative.
Thanks for the heads-up.
Sounds like things getting faster with that right?
Faster access to the data or do i understand it wrong? :)
Yes faster, because the application's data can be placed in the same database where blocks are.
Congratulations @mickiewicz! Your post has been a top performer on the Hive blockchain and you have been rewarded with the following badge:
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
Interesting i'm new to hive and this was very helpful
Thank you very much for this very interesting article and for how further describing everything within it in the minutest detail backed by great flowcharts as well! Keep up the good work, as usual! :)
That makes sense
Awesome read @mickiewicz, is it like Smart Contract functionality in Ethereum?
Not exactly, execution of HAF application is not a part of the blockchain consensus, blockchain ( i mean layer1 ) is not conscious about the existence of any HAF application and cannot validate its work
Found this through @taskmaster4450 This is exactly what we need to make HIVE attractive to DAPP developers. Ethereum has gained so much attention simply beccause there is a great deal of DAPPs utilizing the blockchain. We need to do the same for HIVE. Currently @splinterlands is doing 99% of the user onboarding and we are likely to exceed our best times (had during STEEM days) with only 1 DAPP.
This is an amazing project. I guess its an added feature on top of hivesql? Dude it will be perfect if you're integrating hive-smart contract on top of this sql beast. You're basically integrating ethereum on top of hive! Its great to see splinterlands massive users doesn't slow us down on hive. Perhaps to maximize the usage of hive is through smart contract!
Why are you downvoting my post @spaminator??
Congratulations @mickiewicz! You have completed the following achievement on the Hive blockchain and have been rewarded with new badge(s) :
Your next target is to reach 600 upvotes.
You can view your badges on your board and compare yourself to others in the Ranking
If you no longer want to receive notifications, reply to this comment with the word
STOPCheck out the last post from @hivebuzz:
$PIZZA Token team!@mickiewicz! This post has been manually curated by the
Learn more about $PIZZA Token at hive.pizza. Enjoy a slice of $PIZZA on us!
lol dec 8 2010 https://www.theguardian.com/news/blog/2010/dec/08/wikileaks-us-embassy-cables-live-updates
Congratulations @mickiewicz!
You raised your level and are now a Minnow!
Check out the last post from @hivebuzz:
hey :) how is the progress ?
will this be an alternative to HiveSQL?
Thx, such positive feedback encourages me to write more posts
eventually they will end up with @telosnetwork fork running inside hive with Hive WItnesses running paralelel telos.net EOSIO block producers so a second chain
so youre a hive witness? You also become a telos witness but on a special fork of telos made JUST for hive witnesses to plug into and use for eosio smart contracts like ethereum and we can use the ethereum virtual machine.... and smart contracts with telos inside hive and have this sort of telos engine emerging inside of hive