식단 계획에서의 최적화 문제 정의: 인공지능 적용을 위한 첫걸음에 이어서, 식단 계획을 위해 정의된 최적화 문제에서 어떠한 방식으로 최적 식단을 찾아야 하는 것인지에 대해 살펴보도록 하겠습니다.안녕하세요, @doctorbme 입니다. 이번에는 저번 글 -
저번 글에서 식단 선호도 함수 f에 대해 제한조건 h,g 를 바탕으로 f를 최대화하는 식단의 집합 x를 찾는 것이 결국 핵심이라는 것을 말씀드렸습니다. 그리고 이러한 제한 조건은 각 개인마다 달라질 수 있으며, 제한 조건을 어떻게 잘 설정하느냐가 결국 개인의 상태를 반영하는 중요한 조건이기도 할 것입니다.
온톨로지(ontology)
어떠한 지식 그리고 이러한 지식 구조를 컴퓨터가 처리할수록 옮겨놓기 위해서는, 종종 온톨로지(ontology)의 개념을 차용할 필요가 있습니다. 결국 우리가 가지고 있는 지식은, 각 요소들 간에 연관이 되어 있으며 계층적인 관계를 가지기도 하기 때문입니다.
온톨로지는 크게 4가지의 구성 요소로 나눌 수 있습니다.
- 클래스(class) : 어떤 것을 지칭하는 개념을 이야기 합니다. 예를 들어, 반찬, 주식, 디저트, 차(tea)와 같은 것을 정의할 수 있겠습니다.
- 인스턴스(instance) : 클래스에 비해 좀 더 실질적인 것을 나타냅니다. 예를 들어 김치, 미역국, 당근케이크, 홍차 등을 나타냅니다. 하지만 인스턴스 또한 클래스가 될 수 있습니다. 김치를 다시 총각김치, 열무김치, 겉절이, ... 등으로도 나눌 수 있기 때문입니다.
- 속성(property) : 속성은 클래스나 인스턴스를 특정한 숫자(값)와 연결합니다. 예를 들어 (여기에서 정의된) 김치는 100g의 무게를 가지고 있다. 몇 그램의 나트륨을 가지고 있다: 이렇게 속성을 정의할 수 있습니다.
- 관계(relation) : 각 클래스나 인스턴스 간에 관계를 정의할 수 있습니다. 예를 들어 총각김치는 김치다. (isA) 이는 포함관계를 나타내므로, 각 클래스/인스턴스를 계층적으로 연결하여 표현할 수 있습니다.
이러한 온톨로지를 정의하면, 해를 구할 때, 약간의 변화를 줄 수 있습니다. 예를 들어 김치와 같은 계층적 깊이를 가지는 반찬 (깍두기, 단무지) 으로 치환해서 해를 구할 수도 있는 것이지요. 결국 우리는 최적의 식단을 구할 때에, 어떻게 하면 빨리 계산할 수 있는가, 효율적으로 해의 공간 안에서 탐색할 수 있는가가 중요해지기 때문에, 이러한 치환은 중요합니다.
특히, 우리가 최적 메뉴를 찾았다고 해서, 매일매일 똑같은 음식만 먹기에는 지루해할 수가 있기 때문에, 오히려 이러한 변화(variation)는 식단 추천에 있어서 오히려 적절하게 권장됩니다.
최적 식단을 찾기 위한 알고리즘
앞에서 정의한, 식단 추천을 위한 최적화 문제에서 f,g,x를 정의하였다면, 이제는 실제 x를 찾아나가는 것이 중요합니다. 사실 다양한 방법론들을 적용할 수 있지만, 여기에서는 크게 세 가지의 방법론을 제시해보도록 하겠습니다.
- 선형계획법(Linear Programming)
- 사례기반추론(Case-based Reasoning)
- 유전알고리즘 (genetic algorithm)
1.선형계획법
선형계획법은 목적함수와 제한조건에 대한 함수를 모두 선형으로 놓고, 최적의 해를 구하는 방법입니다. 앞서 식단의 선호도 함수 f를, 각 식단에 포함되는 음식의 선호도의 합으로 정의하고, 각 음식에 일종의 가중치를 둔다면, 이러한 선형 조합이 가능합니다.
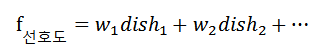
선형계획법의 장점은, 비교적 해를 빨리 구할 수 있다는 것입니다. 여기서 빨리라는 의미는, 알고리즘의 시간복잡도(time complexity)가 그렇게 높지 않다는 것입니다. 사실 선형으로 놓고 풀면 장점이 많은데, 쌍대성 조건을 통해 원래의 문제(primal) 를 대응되는 문제(dual)로 바꾸어서 풀수도 있고, 해가 어느 범위에서 존재할지 경계(bound)를 살펴볼 수도 있습니다.
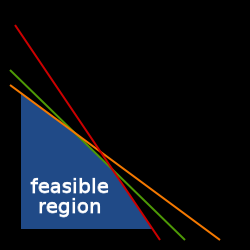
그림1. 선형계획법의 제한조건과, 가능한 해 집합
위 그림에서 살펴볼 수 있듯이, 제한 조건이 부가됨에 따라, 가능한 해 영역이 다듬어집니다. 가능한 해 영역 안에서 f를 최대화하는 x를 찾으면 됩니다.
2.사례기반추론(Case-based Reasoning)
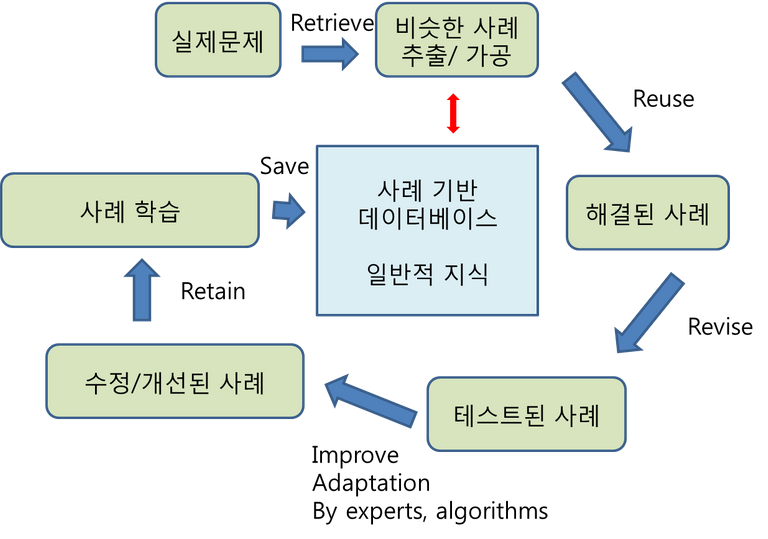
그림2. 사례 기반 추론의 한 예
사례기반추론을 간단히 요약하자면, 기존에 저장된 사례를 바탕으로, 새로운 문제에 대해 기존 사례를 이용하거나 수정/개선하여 다시 새로운 사례를 학습하고, 이를 계속 저장해나가는 방식을 뜻합니다. 이를 식단 구성에 응용하기 위해서는, 특정 조건을 가진 사람들(정상인 포함)에 대해 이미 잘 설계된 식단들의 집합을 이미 데이터베이스에 어느정도 가지고 있는 것이 중요합니다. 이를 바탕으로 새로운 사람 혹은 새로운 조건이 등장하였을 때에, 기존 사례를 바로 출력하거나 수정해서 내놓는 것이 가능하겠습니다.
이 때에는 지식의 형태를 어떻게 저장하느냐가 중요한 이슈 중 하나인데, 비슷한 사례를 어떻게 파악하고 찾을 것인지에 대한 문제를 해결하기 위해서는, 각 속성 간에 비슷하고 비슷하지 않는 것을 잘 정의하고, 속성/인스턴스/클래스 간의 계층적 구조가 잘 정의되어 있어야 합니다. 이 때, 추출된 사례가 제대로 된 사례인지 아닌지를 판별하는 과정에서 알고리즘의 도움 이외에, (식단/영양) 전문가의 지식/의견을 개입시키고 반영할 여지가 있습니다. 이는 사례 별로 일종의 제한 조건을 걸어주는 것과 유사하다고도 볼 수 있습니다.
3.유전알고리즘 (genetic algorithm)
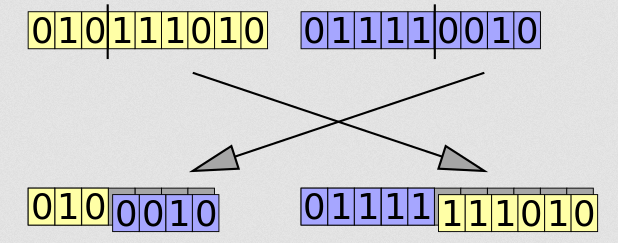
그림3. 유전 알고리즘 중 cut and splice 의 한 예
우리가 정의하는 함수 f가, 항상 선형이거나 볼록(convex)하지 않을 수도 있습니다. 그렇다면 이러한 함수를 최대화하는 해를 찾는 방법에 있어서, 국소적 최적해를 찾을수는 있으나 이 것이 전역적으로 최적해일지는 알 수 없습니다. 그럼에도 불구하고, 각 식단들의 조합을 통해 주어진 함수f의 조건을 만족하는 해를 찾아나갑니다. 이 때 유전알고리즘은 우리가 익히 들어 알고 있는 다양한 유전적 변화의 메커니즘을 가정합니다. 주어진 두 개의 식단에 대해, 식단의 일부를 서로 바꾸거나, 기존 식단의 일부를 다른 것으로 갑자기 바꾸거나 (돌연변이) 하는 등의 방법을 취합니다. 여러 식단들이 각각 이렇게 변형되다보면, 일정 기준을 만족하는 식단을 찾을 수 있습니다. 그러면 이 때 이 식단을 출력하면 됩니다.
제가 생각하기에 유전알고리즘을 사용할 때의 장점은,
- 어차피 다양한 식단을 여러개 제공해야하는데, 국소 최적해들 여러개 찾는 것은 결국 식단의 다변화성을 나타내므로 사람에게 좋다
- 의도하지 않은 새로운 식단이나 음식의 조합을 찾아낼 수 있다.
입니다.
식단 추천 알고리즘에서 최적 식단을 찾는 방법들과 특성을 살펴보았습니다. 위에 제시된 알고리즘 이외에도 다양한 알고리즘을 적용하는 것이 가능할 것입니다. 중요한 것은 1) 식단을 어떻게 하면 빠르고 다양하게 찾을 것인가이고, 2) 지식의 구조를 반영하며 수정할 수 있을 것인가에 대한 관점을 살펴보는 것이 되겠습니다.
다음번 글에서는 각 사용자의 상황에 따라 어떻게 제한조건을 각기 부여할 수 있는지에 대해 고찰해보도록 하겠습니다. 읽어주셔서 감사합니다.
참고문헌
[1] Khan AS, Hoffmann A. , Building a case-based diet recommendation system without a knowledge engineer, Artif Intell Med. 2003 Feb;27(2):155-79.
[2] Gaál B, Vassányi I, Kozmann G. , A novel artificial intelligence method for weekly dietary menu planning. , Methods Inf Med. 2005;44(5):655-64.
[3] Johan Aberg, Dealing with Malnutrition: A Meal Planning System for Elderly, AAAI Spring Symposium: Argumentation for Consumers of Healthcare, 2006
[4] Alessandro Mazzei, Luca Anselma, Franco De Michieli, Andrea Bolioli, Matteo Casu, Jelle Gerbrandy, Ivan Lunardi, Mobile Computing and Artificial Intelligence for Diet Management, ICIAP 2015 Workshops pp 342-349
그림 출처:
그림2: 자체작성
그림1: https://en.wikipedia.org/wiki/Linear_programming , public domain
그림3: https://commons.wikimedia.org/wiki/Category:Evolutionary_algorithms , Creative Commons SA 3.0


정보를 주셔서 대단히 감사합니다. 이것은 매우 유용합니다. 허용되는 경우이 기사의 정보를 유지합니다 ... 감사합니다.
Thank you for reading. If possible, you may make English comments on this article, not translated Korean sentences.
thank you @doctorbme for your response, fore I will comment with English, sorry if my English is not good, I am native Indonesia.I'm new to this steemit platform ...
제가 만약에 로직을 설계한다면 선형방식을 선택하겠네요.
사례와 유전은 접근 방식이 좀 어려워 보이네요.
제일 간단하게 구현할 수 있는게, 말씀주신대로 아무래도 선형계획이지 않을까 싶습니다. 가장 기본이 되는 것이기도 하기 때문에, 이 방식만 잘 구현해놓아도, 다른 방법론으로 확장/응용이 가능할 것입니다. :)
@yourwisedentist님이 당신의 글을 번역 요청했습니다Powered by Steemit Translation by CICERON