Maybe I would be answer some questions here, as a witness and operator of full API node that is used by various service providers on Steem.
Is the issue described in @elfspice's comments real?
From what he described it seems that he has real issues,
however Steem platform is fine.
Is the issue described in @elfspice's comments as serious as they seem to be?
For him? Yes. For platform? No.
My full API node is operating on a single, low-end dedicated server with amount of RAM as on my few years old workstation.
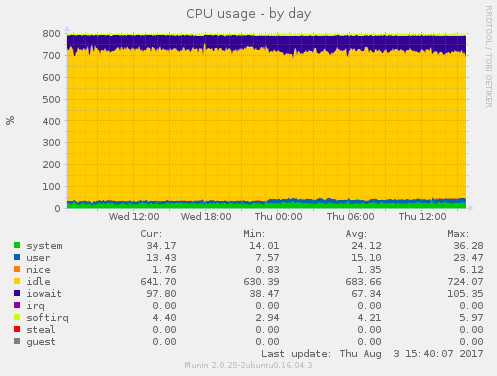
At this very moment it is serving 65 connections per second (average from 100 seconds). Disk latency is 2.6 - 4.0ms.
Of course there are some performance challenges that we witnesses, and others: community developers, Steemit Inc developers etc are aware of, those are being addressed, way ahead of time, but FUD-spreading-troll level talk is not even close to what I would like to spent my time on.
If this is not an issue, it is important to expose @elfspice as a source of FUD. I do not believe that to be the case right now. I think there is cause for concern.
It's not an issue and @elfspice is a source of FUD. Not for the first time.
Hey there @gtg, I'd love it though if you would make a tutorial maybe on making a Full API node in best practices?
I use your node for my upcoming app, so it would be nice to make a few more for some load balancing and etc.
If I would have time for that...
Actually this is pretty straightforward, as long as you are not expecting to run it on potato-grate hardware ;-)
Also, a lot depends on certain needs. Not all the people needs really full node with all plugins. Most of people doesn't. Like for example exchanges mentioned by that troll are not using full nodes.
Most info needed to successfully run your node is in docs. You might want to modify that depending on your exact needs. Feel free to catch me on steemit.chat as Gandalf but expect some delays with answers.
I would gladly help with setting up public nodes.
BTW, I'm able to have considerably low amount of RAM mostly because I have decent speed on my storage backend. Current setup is very cost effective, however I'm running out of space (storage is fast but small, as I have 3 disks combined)
Ah, so instead of having 128GB RAM, you're using SSDs in RAID 5 for your swap backend?
RAID1
Of course having 128GB of RAM to keep there everything would be nice, but not cost effective.
I very much appreciate your extra clarity on this issue, but it does sound to me like that architecture won't scale beyond a few months without major work. I hope there are plans in place, and that Steem Inc. can communicate better on this issue in future.
Thanks again though!
@gtg thank you very much for offering your observations. I really appreciate it. I hope others do. When there is limited communication from the people that know these things, there is ample room for doubt. The majority of steemians, myself included are not technical. There are clearly issues but none of us know how serious they are and it is difficult to put things into context at times. None of us can read everything on here. I did not know that elfspice had spread FUD before.
Do you know why exchanges seem to be having difficulty offering a stable service for steem?
Currently there are crazy times because of Bitcoin. Aside from that:
Bittrex is indeed having some delays recently but they are great at communication and I think we would be able to help them improve reliability.
Blocktrades is working flawlessly.
Poloniex well... multiple attempts to contact them, they were down today for hours... that's not related to Steem at all.
Thank you @gtg
So, a virtual machine with 10 cores and 50gb of ram, that was doing just fine running a witness, and 3 months ago was running an RPC fine, and, a Ryzen7 1700, which I established I had to update a kernel to fix that problem, both somehow cannot replay the full chain, for an RPC, BOTH RUNNING UBUNTU 16.04, LATEST.
Prove you are not lying by taking a person, who has not had any dealings with you in the past, and helping them get an RPC up and running.
Because bittrex is having a problem.
Poloniex is basically refusing to deal with it anymore, they got bigger fish to fry.
Tradequik, over 48 hours 'routine, automated maintenance
Shapeshift quit dealing with Steem at least 2 weaks ago.
So, stop lying. What keeps your RPC up and running, and why is it that me, and 4 major, high end operations, cannot keep a
steemdrunning?Let us know what the secret is, or admit that you have much more fancy hardware, paid for with your premined stake, than you are admitting to.
I know enough about sysadmin to know, that your front end, could be bumping traffic to any number of backends. You could have over 10 Steemd nodes running, on a failover, and nobody would know, unless they could monitor the in-and-out on your server.
@furion thinks the following, which supports your hypothesis:
https://steemit.com/steem/@furion/updates-on-steem-python-steemdata-and-the-node-situation
No wonder I was having trouble on a 50Gb xeon VPS with 10 cores and a 1.2tb SSD. When I started, back in November, this was still a bit difficult but it only needed about 32gb. In 6 months since, that requirement has quadrupled. If it quadruples again, there isn't a computer on the planet that sits inside one box, that can run this thing.
I'm not gonna hold my breath for an apology from these pigs who have been blatantly lying through their teeth.
Graphene, so great, it needs 128gb to run a 1 year old blockchain.
So, who's lining up to be part of Dan's next project?
Yes, no wonder, I see why you're bitter about this! It does make me feel sick, and the lies are really disappointing!
If EOS stores a more sensible amount of info in the blockchain though, it could be much more sustainable even if it's very similar underlying technology. Don't you agree?
I reckon he's probably learnt his lesson (technically), moved out and done something with a genuinely better architecture, though I don't know how good of course, and trust is pretty important!
Yeah, maybe he learned the error, but his narcissism prevents him from admitting his error.
Also, if EOS borrows from Ethereum, then it uses multiple backend data stores and not just one giant monolith. Different types too.
Hey lok1! We at TradeQwik were performing some upgrades across servers and adding a few( 4 new). STEEM was not the reason for our routine maintenance. Thanks man
I'm sorry, I can't help you. That would be an illegal medical practice.
I've explicitly offered (and provided) help to people that needs API nodes for their businesses and reported on my own node status multiple times in my witness logs.
Seriously? That is what you see there?
Are you seriously screenshootting content that was written on the blockchain?
You are insane*
(*) that's my subjective point of view, unfortunately, I'm not a doctor so I can't provide you a medical advice = "that would be an illegal medical practice"
Please seek your help among doctors, not witnesses.
Good luck.
Is anybody else having this issue other than elfspice? What problem could he have if you're facing none?
Already discussed. BKAC kind of problem that he fails to acknowledge blaming the rest of the world.
Thanks for clearing the air. Followed both you and elfspice. Good to listed to both the sides of the argument. Nice names by the way Loki and Gandalf the Grey.
Thanks @gtg.
What amount of RAM does your full API node have?
32GB currently, but that would flawlessly only with decent speed on storage backend (a lot of I/O has to be handled)
Thank you. We are trying to understand the discrepancy between what you're saying at what @furion is saying here:
https://steemit.com/steem/@furion/updates-on-steem-python-steemdata-and-the-node-situation
Can you help any further, to put this issue to bed, so I can keep investing my time in this great project?
As far as I can see, @furion seems to be satisfied with my node. Of course funding clusters of such ( or even better - much bigger ) nodes is always welcome.
It was the 128GB versus 32GB RAM difference that I was getting at, but now you've explained that you use SSD drives for swap it reconciles the apparent discrepancy for me. Thanks.
Ah, I see. Everything depends on exact environment. Low latency is crucial especially at initial reindexing. For example my 64GB backup API node performs much slower (at least at reindex) because it has a single SSD drive.
Oh right. I've been considering setting up a witness, but would only be interested in a full RPC node, as I'm doing development with RPC ( @steemreports).
Given that I'd need to do it remotely, so won't have access to the hardware, is there a suitable provider and server you could recommend? I getting the impression a VPS isn't going cut it for a number of reasons.
I'd very much appreciate any pointers.
Yes, indeed, you had a chance for that long time ago...
That would be before you've made your platform-leaving-FUD-performance with @faddat.
Just to remind you: you've used alleged issue with steem as an excuse for that. When I pointed out that it's not true and steem is working as expected then you've blamed @xeroc's python-lib which turned out to be your lack of understanding how it works.
Good luck with The Dawn.
The Steemians send their regards.
Why do you keep commenting on 2 of your separate accounts?