English version below
PT
Esta é a parte 6 da série de criptografia. Se você não viu as partes anteriores veja abaixo:

Source
Criptoanlise em cifradores monoalfabticos
Aqui vamos aprender uma forma simples de quebrar uma cifra monoalfabética. Como as letras são apenas substituídas, temos 4x10^26 possibilidades possíveis. Ou seja, coisa para caramba para quebrar com fora bruta, o que não vamos fazer. Para isso temos outra técnica, a análise de frequência.
Como esse algoritmo apenas substitui as letras por outras, a frequência de aparição de cada letra não muda, ou seja, analisando a frequência que a letra aparece no texto, é possível deduzir qual é o texto claro. Para auxiliar nesse processo temos uma tabela que informa a frequência que cada letra do alfabeto aparece em média em um texto.
Veja abaixo as tabelas de frequências de letras em português e em inglês:
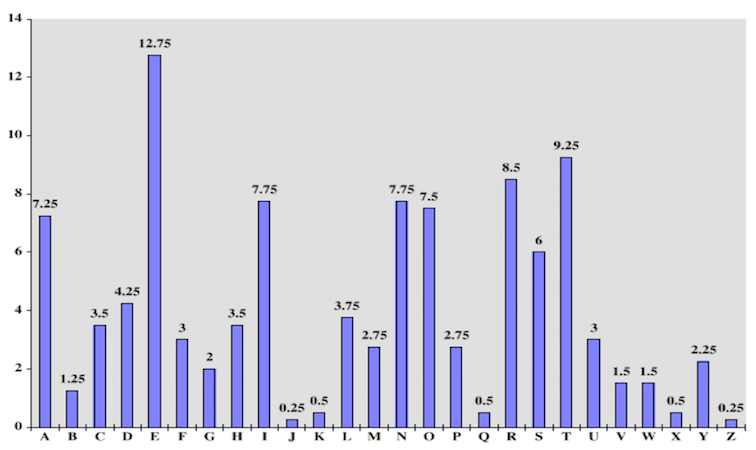
Frequência de letras em inglês
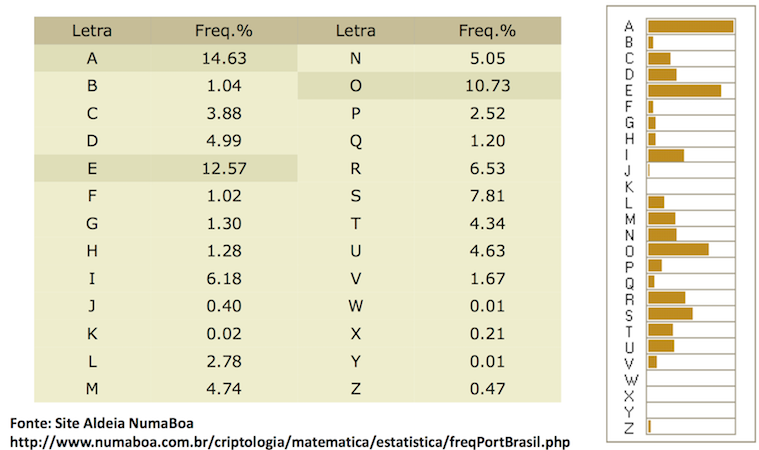
Frequência de letras em português
Ainda no entendeu? Vamos ao exemplo:
Se no texto cifrado a letra que mais aparece é a letra P e você acredita que o texto esteja em português, olhando para a tabela, podemos assumir que o P do texto equivale a letra A, que é a que mais aparece no idioma português. Agora é só substituir todos os Ps por As e fazer a mesma coisa para outras letras. Assim que você já tiver algumas letras substituídas você pode começar a identificar pequenas palavras como da, do, por, para, se, sim, no, com, etc.
Uma observação importante. Quanto maior o texto mais fácil de fazer a análise de frequência. Se o texto for muito pequeno a frequência pode se alterar.

ENG
This is the sixth part of the cryptography series. If you didn't read the previous posts see below:
Source
Cryptoanlysis in monoalphatic ciphers
Here we will learn a simple way to break a monoalphabetic cipher. Since the letters are only substituted, we have 4x10 ^ 26 possible possibilities. That is, hard thing to break with brute force, which we will not do. For this we have another technique, the frequency analysis.
Since this algorithm only replaces the letters with others, the frequency of appearance of each letter does not change, that is, by analyzing the frequency that the letter appears in the text, it is possible to deduce which is the clear text. To assist in this process we have a table that tells how often each letter of the alphabet appears on average in a text.
See below the tables of frequency of letters in Portuguese and English:
Frequency of letters in English
Frequency of letters in Portuguese
Still do not understand? Let's look at the example:
If in the ciphertext the letter that appears the most is the letter P and you believe that the text is in English, looking at the table, we can assume that the P of the text is equivalent to the letter E, which is the one that appears the most in the English language. Now just replace all Ps by Es and do the same thing for other letters. As soon as you already have some letters replaced you can begin to identify small words like no, from, to, yes, on, with, do, for, etc.
An important note. The larger the text, the easier it is to do the frequency analysis. If the text is too small, the frequency may change.





