
인공지능 관련 포스팅을 위해 알파고에 대해 좀 더 자세히 공부하면서 생각이 좀 많이 달라졌다. 2016년 3월 이세돌을 4:1로 누른 '알파고 리'는 1202개의 CPU와 176개의 GPU로 구성된 막강한 계산능력을 갖춘 인공지능이었다. 존경하는 도올 샘께서도 이 대국을 두고 "인간이 계산기를 이길 수 있겠느냐"며 대결의 부당성마저 제기하였다. 필자 또한 반은 그렇게 생각했다. 그러나...
작년 3월 세계 최정상 프로기사를 처음으로 누른 '알파고 리'에서 시작하여 올해 5월말 바둑 세계 랭킹 1위인 커제를 3:0으로 가뿐하게 누른 '알파고 마스터' 그리고 이 '알파고 마스터'를 100:0으로 완패시킨 '알파고 제로'!
알파고는 이렇게 엄청난 속도로 진화하면서 단순한 계산 능력이 아닌 인간의 사고를 흉내내는 알고리즘의 발전으로 이어지고 있는 것을 보고 생각이 바뀌지 않을 수 없었다.
자~ 그럼 알파고는 어떻게 정의되는 것일까?
몬테 카를로 검색 방식을 적용하여 13층의 컨벌루션 신경망으로 지도학습과 강화학습을 통해 만들어진 가치망과 정책망으로이루어진 바둑 전용 인공지능이다.
무슨 말인지 하나도 모르겠다!!!
사실 신경회로망을 주제로 석사학위를 받은 필자도 한번에 이해가 안되는데 비전공자들이 이것을 이해하기란 쉽지 않을 것이다. 하지만 가능한한 이해하려고 노력해보자. 인공지능이 미래의 트렌드임이 확실한데 나만 무식하게 살 수는 없지 않은가? ㅎㅎ
몬테 카를로 검색(MCTS, Monte Carlo Tree Search)
몬테카를로(프랑스어: Monte-Carlo, 모나코어: Monte-Carlu, 오크어: Montcarles)는 모나코를 구성하는 10개 행정구 가운데 하나이다.[1] 종종 모나코의 수도로 오해되기도 하나 이는 사실이 아니며, 도시 국가인 모나코의 수도는 모나코 영토 전체이다. 지중해 연안의 리비에라 해안에 위치하고 있는 몬테카를로는 프랑스가 그 주변을 둘러싸고 있으며, 이탈리아와도 매우 가깝다.거주 인구는 약 3,000명이다. 카지노와 도박장으로 유명하다. from 위키피디아
카지노로 유명한 모나코의 도시의 이름을 딴거 보면 이것은 무작위 선택(random choice)를 썼다는 것이다. 도박도 확률 게임이기는 하지만 수학 계산과는 달리 인간의 감(hunch), 즉 통박이 주요한 선택 방법이기 때문에 검색 알고리즘의 이름을 이렇게 붙인 것이다.
바둑은 그 경우의 수가 우주에 존재하는 원자의 갯수를 다 합한 것보다 많다고 하니 단순히 모든 경우의 수를 다 검색 판단하는 것(이것을 brute-force 방식이라고 한다)은 불가능하다. 따라서 알파고가 다음 수를 둘 때는 이러한 인간의 통박과 비슷한 알고리즘을 사용한다는 것이다. 사실 이것이 난공불락이라고 여겨지던 바둑의 세계를 인공지능이 접수하게된 가장 중요한 열쇠가 된다.

위의 그림처럼 몬테 카를로 검색 방식을 적용하게 되면 가지마다 깊이가 다르게 된다. 즉 가치가 있는 판단에 대해서만 깊이 생각하는 것이다. 인간과 동일하지 않은가?

알파고는 이러한 몬테 카를로 검색 방식을 적용해서 선택 -> 확장 -> 시뮬레이션 -> 역전파 과정을 계속 반복하여 이길 수 있는 수를 찾아낸다.
컨벌루션 신경망(CNN, Convolution Neural Network)
Time domain에서 두 함수를 컨벌루션하면 Frequency domain에서는 두 함수를 곱한 것과 같다.
f(t) = g(t) * h(t) => F(s) = G(s) x H(s)
대문자와 소문자는 라플라스 변환 관계
여기서 * 는 컨벌루션 연산을 의미하고 x 는 곱하기 연산.
그런데 여기서 말하는 컨벌루션 연산은 쉽게 말해서 이미지 필터링이다. 이렇게 이미지 필터를 적용하는 이유는 말할 것도 없이 인공지능 즉 컴퓨터가 계산하기 쉽게 만들어주기 위한 것이다.

인간은 왼쪽 사진을 보고 개와 배경을 쉽게 구분하지만 컴퓨터는 에지 필터(여기서는 Edge filter를 컨볼루션했다)를 이용하여 윤곽을 분리한 뒤 개인지 아닌지를 구분하는 것이다.
그렇다면 알파고에 왜 이미지 필터를 적용하는 것일까?
그렇다! 알파고는 돌이 놓여진 바둑판을 이미지로 인식하고 처리하는 것이다.
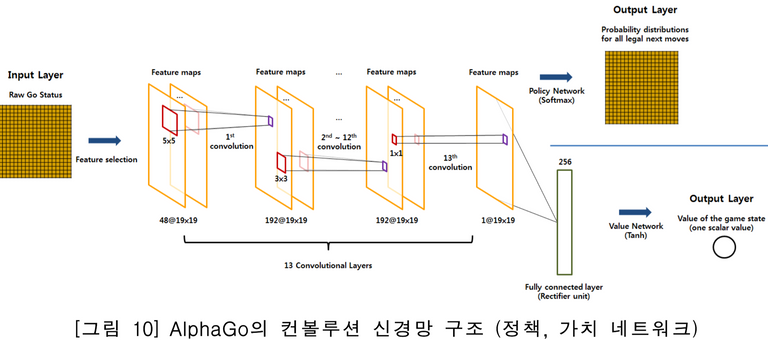
위의 그림 중간에 보여진 convolution layer가 모두 13개이고 그래서 D.E.E.P.~ 하다는 것이고 이를 Deep Learning이라고 부른다.
지도학습(SL, Supervised Learning)과 강화학습(RL, Reinforcement Learning)
알파고는 수천만가지의 기보를 익혔다고 전해진다. 이렇게 기존 기보를 가지고 프로기사들이 두는 다음 수를 모두 classification 하는 방법으로 학습시키는 것을 지도학습이라고 한다.
하지만 지도학습만 가지고 반드시 승리한다는 보장이 없고 또 바둑이 진행될수록 같은 수를 놓은 경우가 적어지기 때문에 스스로 바둑을 진행하면서 수를 익히는 자가 학습법인 강화학습을 통해서 승률을 올린다. '알파고 제로' 버전이 놀라운 것은 바둑의 규칙만 알려주고 오로지 강화학습을 통해서 기력을 올렸다는 점이다. 이런 이유로 알파고가 수많은 기보를 익혔기 때문에 최정상의 프로기사를 이겼다는 해석은 설득력이 없다.
정책망(Policy Network)과 가치망(Value Network)
정책망은 주어진 현재 상태를 고려하여 다음 수를 결정하는 데 있어서 확률분포를 적용한 개념이다. 이건 또 뭔 소리여???
최대한 쉽게 설명하자면 같은 입력에 대해 다른 출력(결과물)이 나올 수 있다는 것이다. 엑셀에 수식을 만들면 어떤 경우라도 같은 입력에 대해선 같은 출력이 나와야한다. 하지만 몬테 카를로 검색 방식에서는 다른 결과가 나올 수 있다는 것이다. 앞서 언급하였듯이 이러한 선택 방법이 알파고를 인간과 보다 가깝게 만들어준 중요한 열쇠이다.
정책망과는 달리 가치망은 이 수를 통해서 얻어지는 승패의 결과를 알려준다. 가치망의 결과값은 Win or Lose이다. 알파고는 가치망을 통해 승패를 판단하는데 현재판에서 둘 수 있는 어떠한 수를 두어도 가치망의 결과값이 Lose가 나오면 주저없이 돌을 던진다.

"AlphaGo resigns"
이세돌이 알파고와의 4번째 대국에서 통쾌한 승리를 거두었던 역사적 장면이다. 필자는 당시 5국 전체를 실시간으로 시청하였는데 이 4번째 대국이 인간이 인공지능을 상대로 이겼던 마지막 대국이 될 것이라는 것을 직감하였고 슬프게도 그것이 실제로 현실이 되고 있다.
PS : 이번 포스팅은 좀 힘든 작업이었습니다. 솔직히 100% 이해하지 못하는 주제에 대해 비전공자들이 이해하기 쉽게 쓴다는 것이 몹시 어려웠습니다. 혹시 제가 언급한 내용 중에 틀린 내용이 있으면 가차없이 댓글 달아주시기 바랍니다. 정확하게 오류를 지적해 주시면 기쁜 마음으로 풀 보우팅 해드리겠습니다.
그리고 알파고에 대해 제가 올린 것보다 더 재미있고 이해하기 쉽도록 포스팅해 주시면 풀 보우팅은 물론이고 상금으로 50 SBD를 송금해드리겠습니다. ㅎㅎㅎ
Cheer Up!
우와 아주 흥미롭습니다👍
만약 알파고를 구글(딥마인드)이 아닌 애플에서 만들었다면...
아이고...가 되었을거라는군요. ㅋㅋ
ㅋㅋㅋ 예상치 못한 개그에 빵 터졌네요..ㅋㅋㅋㅋ
탐구하시는 모습이 정말 멋집니다 루비메이커님 +_+ b
요곤 6일차쯤~ 리스팀으로 가져가도 되겠죠? ^^
아~ 들인 노력을 이해해주시니 정말 감사합니다. ㅎㅎ
저는 알파고를 친구들끼리 드립칠때나 써봤지,, 자세히 읽어본건 첨인거같아요!!
컨벌루젼 레이어를 히든 레이어라고도 한다는군요
재미있게 읽었습니다!
아~ 히든 레이어는 input과 output이 아닌 내부에 감춰져 있다는 뜻이구요. 컨벌루션은 본문에서 설명드린대로 (이미지 ) 주파수 영역에서 필터링을 적용했다는 뜻입니다.
다시 말해서 히든 레이어에 컨볼루션이 아닌 다른 어떤 것도 올 수 있지요. 굳이 이미지 처리가 필요없는 알고리즘은 컨벌루션을 쓰지 않겠지요. 물론 이미지 처리가 아닌 컨벌루션도 있습니다만 컨벌루션과 히든 레이어는 별개의 것으로 이해하지면 될 것 같습니다. ㅎㅎ
아 그렇군요. 비슷한 메커니즘으로 보여서 동일한것으로 생각했습니다.ㅎㅎ
알파고 관련 흥미로운 포스팅 잘 읽었습니다. ^^
안녕하세요 rubymaker 님, 정말 저도 그 대국에 관심이 있었는데요 지금 그 화면을 다시보니 가슴이 찡 함을 느끼게 되네요. 저도 비 전문가의 입장에서 그저 신기함으로만 받아들이고 있었는데요 공부를 많이 하시고 포스팅하신 흔적이 많이 보이는 것 같습니다. 감사합니다. 행복한 연말 보내시길 바랍니다^^
감사합니다.
연말 잘 보내세요.
넵~ 감사합니다^^
바둑 대전을 비록 저는 보지는 못했음에도
다양한 곳에서 실감하고 있습니다.
라는 사실을 말이죠
그렇기에 가치가 한없이 높은 대국이라고 봅니다
잘 보고 가요
그렇습니다.
이세돌은 비록 패했지만 알파고를 더욱 진화시켰지요. 대단한 일을 해낸 것입니다.
좋은글 잘읽었습니다. 저는 비전공자에 특히 수식에 약한지라 상당히 이해하기 힘든 면이 있지만 말씀하신데로 앞으로 이해하려고 노력해야하는 분야라고 생각합니다. 이미 일본에서도 Ai는 생활 곳곳에서 발견되고 있고 적용되고 있기때문이죠. 앞으로도 인문학적으로나 인류학적으로나 상당히 중요한 기술적 전환기가 이미 찾아온듯한 느낌이 강하게 듭니다.
안녕하세요 뉴비에요! 알파고에 대해 몰랐는데 정보 얻고 가요!ㅎㅎ
사실 이해하는 걸 풀어 설명하는게 더 어려울수도 있습니다. 그것도 비전공자 분들께는 더욱더~ 저도 혼자만 공부할게 아니라, 좀 더 쉽게 널리 공유하는 것에 대해서도 생각해 봐야겠습니다. 수고하셨고, 잘 봤습니다.
알파고와의 첫 대국에서 모든 프로와 아마추어 기사들은 인간의 승리를 예견했지요
저 또한 인간이 이길 거라 믿어 의심치 않았습니다.
결과를 대패였지만 말이죠..
알파고가 버전 업하면서 나타난 알파고 제로 또 한 굉장한 충격이었습니다.
이전에 프로 기보를 학습했던 알파고 시리즈와 다르게 규칙만 입력된 상태에서 급격한 실력 향상을 보인 후 최고의 실력을 내었으니까요
결국 현대의 프로기사들이 알파고의 수를 연구해서 두고 있는 현실이 되어버렸네요. 체스 챔피언이 컴퓨터에게 졌을 때도 바둑은 수가 워낙 무궁무진하여 절대 지지 않는다고 하였는데 기술의 발전은 어쩔 수 없나 봅니다 ㅎㅎ
잘 읽었습니다.좋은 정보 감사합니다.오늘도 좋은날 되세요
루비님 정말 감탄하며 글을 읽어내렸어요~~ 사실 전 이런쪽엔 정말 문외한이지만 글을 읽으며 가끔 고개도 끄덕였답니다~~ 히힛~~
읽다보니 알파고가 우리 가까이에서 생활하게 될 날이 머지 않았겠구나 하는 생각도 드네요~ ^^
조심하세요!
AlphaGo의 셰프 버전 AlphaCook이 나와서 요리를 대신할 지 누가 압니까? ㅋㅋ
어렵지만 인공지능에 대해 조금은 알게되는 흥미로운 글이었습니다~끝까지 못 읽고 포기 할 뻔 했는데.. 중간에 '이건 또 뭔 소리여' 라고 작가님이 제 마음의 소리를 대변해주셔서 웃으며 완독했습니다~ㅎㅎ 다음 포스팅도 기대하겠습니다~~^^
알파고 주제 참 반갑네요. 제가 평생을 바둑과 함께 살아온 입장이라 더욱 느끼는 바가 큽니다. 여기 스팀잇에서는 바둑이야긴 일체 안하고 있습니다만....알파고는 인간의 불안정을 완전히 넘어선 존재라는 생각이 들어요. 저도 예전에 신이 있다면 몇점을 깔겠는가....에서 석점을 제시했던 기억이 납니다. 지금의 알파고가 바로 그 영역이라고 느껴지네요.
그런데 더 강한 존재도 나오겠지요? 휴우......
우어 정말 잘 보고 갑니다 다 이해는 못해두 너무너무 재밌게 읽었어요 ㅎ 스팀잇유저라는게 참 고마운 순간이네요 ㅎㅎ
감사합니다~~
인공지능이 어디까지 발전하여 인간의 사고를 대신할 날이 올런지 궁금하긴 하네요
어느 정도까지는 '대체'보다는 '상호보완'에 쓰이지 않을까요? 머신이 내려놓은 결론을 인간이 보고서 판단하는데 도움을 받는 선에서 꽤 오래동안 머무르지 않을까 싶습니다. 모든 영역에서 완전히 대체하기에는 인간의 두려움이 너무 클 것 같아요.
알파고가 함께할 미래는 편리하기도 하지만 무섭기도 하네요..
복잡하고 생소한 인공지능 개념의 포인트들을 간결하고 이해가 잘 가게 설명해주셔 감사합니다. 읽다가 궁금증이 생겼는데 컨볼루션 신경망 구조에서 알파고가 바둑판을 이미지로 이해한다는 내용은 바둑판의 각 위치들을 하나의 픽셀로 간주하고 놓인 위치와 안 놓인 위치를 0과 1에 대응시킨다는 것으로 이해하면 되나요?
그렇습니다.
근실하게 나는 그들을 만나기 위해 앉았다. 훌륭해. 나는 네가 좋아한다. 이 게시물은 좋은 콘텐츠로 내 얼굴에 미소를지었습니다. 그것을 지키십시오.
언젠가...진짜...인공지능이 인간을 대체할 날이 올까요?
흥미로운 글 잘 읽고 갑니다.
감사합니다.
알파고 그냥 대활때 몇번써본거말 고는 딱히 아는게 없는데요
좋은글 잘보고갑니다
아는척쫌 해봐야겠습니다
감사합니다
저도 요즘 애픽스 백서를 번역하면서, 비전공자가 이해하기 어려운 부분이 있어 번역에 애를 먹고 있습니다. 그래서 루비메이커 님이 글을 쓰시면서 느꼈을 고뇌가 느껴지는 듯 하네요. AI에 대해서는 기반지식을 이해하기보다 잘 누리고만 싶은 측인데, 오늘 설명해 주신 [몬테 카를로 방식]은 알아두면 좋을 것 같다는 생각입니다. 감사합니다.
ㅎㅎ
번역하신 에픽스 백서 읽어보려고 합니다.
관심 가져주셔서 감사합니다 ㅎㅎ
https://steemit.com/abuse/@lukestokes/whales-you-have-some-flagging-to-do
Please resteem or promote to finally a good witness that cares about this platform and isnt afraid to stand up to berniesanders....haejins followers upvote my posts and resteem....
.if your a whale or dolphin delegate to me your SP so i can stomp bernie aka justin for good...i delegated all my steempower to haejin already im weak I LOVE YOU KOREA!!!!5